Arkadium: a neuro-symbolic agent anchored to the Meta-Globàlium for structural verification of human judgment in artificial intelligence systems
Opengea SCCL — Barcelona, Catalonia
Abstract
Large Language Models (LLMs) exhibit four structural deficits that scale alone cannot resolve: correctness, transparency, generalization, and efficiency. Recent reasoning models — OpenAI's o-series, DeepSeek-R1, Gemini Thinking, Anthropic Opus and Sonnet — show progress in domains with formal verifiers (mathematics, code, logic) but collapse in human domains where no ground truth exists: ethics, politics, social judgment, public deliberation. This paper presents a concrete technical proposal to overcome this verifier gap.
The technical contribution has two complementary faces: (a) a dispersion completeness function 𝓗(r) ∈ [0, 1] that quantifies, over an explicit relational ontological metastructure, the extent to which a response r integrates the dialectical poles of the model — an epistemic property we call globalistic truth, a non-monological conception of truth that recognizes the irreducible plurality of its access modes (objective and subjective, theoretical and practical, phenomenal and noumenal, plasmatic and mundane), in line with the hermeneutic and communicative tradition (Gadamer, Habermas, Heidegger); and (b) an external canonical basis of ontological directions — the Meta-Globàlium — onto which any model can be projected, compared, and audited in a portable, model-agnostic manner, providing a genuinely external top-down interpretability layer — directions not discovered post hoc from inside the model, but derived from a reflective synthesis of human judgment. This second face is structurally complementary to mechanistic interpretability agendas (Anthropic's sparse autoencoders) and representation engineering (Zou et al. 2023): if the former discovers what is inside the model, ours offers an external, shared, revisable ontological vocabulary to name it. The methodological move is from predictive models — which extrapolate patterns from the training corpus — to judgment models — which evaluate their own output against an explicit relational ontology. Arkadium is an early functional proof of concept of this proposal, offered to public inspection: a conversational agent, RAG framework, and 3D Metamodeler that compute 𝓗(r) at runtime over each response. The framework admits two complementary operationalizations: (i) inference-time — the symbolic verifier wraps an existing LLM with a re-prompt loop and harmonic compensation, currently deployed in production at arkadium.ai; and (ii) training-time — the symbolic stack is compiled into a learned differentiable proxy R̂ that integrates as a multi-objective process reward in standard preference-optimization pipelines (DPO, PPO with PRM), moving the alignment constraint from a wrapper into the geometry of learned weights. We argue that this path — open and sovereign — is structurally necessary to overcome the current ceiling of brute-force scaling combined with textual constitutions. Demonstration available at arkadium.ai.
Philosophical genealogy. This work is inspired by the Globàlium model (Xirinacs 1997, doctoral thesis defended at the University of Barcelona), inherited from the Catalan tradition of integrative thought (Llull → Sibiuda → Pujols → Xirinacs): a 4D hypersphere with 8 primary categories, 26 in the minor model, 80 in the major model, organized along four dialectical dimensions. The Globàlium is philosophical heritage, developed by Xirinacs and cited here as inspiration; it is not part of our work. (i) The Meta-Globàlium (Berenguer / Opengea, 2024–2026) is the formal and computational extension of the Globàlium, from which new axioms and principles are derived and over which the function 𝓗 is defined. (ii) Arkadium (Berenguer / Opengea, 2024–2026) is the agent operating anchored to the Meta-Globàlium as substrate — the verifiable technical artifact that materializes the proposal and tests it. In the Xirinaquian lineage, from this dialectical fullness of truth derives, as normative inheritance, the notion of the Good as harmony between parts — the Good derives from this dialectical fullness, it does not substitute it.
We argue that the necessary movement is from predictive models — which extrapolate patterns from the training corpus — to judgment models — which evaluate the dispersion completeness of their own output against an explicit relational ontology. Arkadium is an early functional proof of concept of this movement, offered to criticism. Our orientation is, moreover, anthropologically explicit: an AI that teaches you to think, not an AI that thinks for you. We argue that technology must equip humans with culture — understood as shared and revisable software — that makes them more self-sufficient, not more dependent; and that a shared ontological framework between humans and artificial agents, far from being an academic luxury, is the structural condition for this relationship to be one of emancipation rather than delegation.
Keywords: AI alignment, neuro-symbolic AI, judgment models, structural verification, shared ontology, AGI, fractal recursion, non-monological truth verification, globalistic truth, dispersion completeness, Process Reward Model, representation engineering, ontological hyperspace, retrieval-augmented generation, Globàlium, Meta-Globàlium, Arkadium, dialectical reasoning, scalable oversight, computational wisdom, top-down interpretability, model-agnostic audit, portable interpretability, canonical direction basis, AI auditability.
Table of contents
1. Meta-Globàlium and Arkadium: two levels of our work
The proposal of this manifest is articulated in two levels of our work — the Meta-Globàlium and Arkadium — anchored in a prior philosophical source of inspiration, the Globàlium of Lluís M. Xirinacs. This source must be distinguished from what is properly our work: the Globàlium is Catalan philosophical heritage developed by Xirinacs and cited here as inspiration; the Meta-Globàlium and Arkadium are formal and computational evolutions developed by Jordi Berenguer and Opengea (2024–2026).
Source of inspiration — The Globàlium (Xirinacs 1997). A global philosophical model of reality, inscribed in the Catalan tradition of integrative thought — Ramon Llull and his Ars Magna (13th c.), Ramon Sibiuda and the Theologia Naturalis (15th c.), Francesc Pujols and the Concepte general de la ciència catalana (1918), through Eugeni d'Ors —, it is the contemporary culmination of a persistent ambition: to offer an exhaustive and revisable cartography of human knowledge capable of accommodating "everything, from God to an espadrille" (Xirinacs 1997). Geometrically, it is a four-dimensional hypersphere; structurally, it contains 8 primary categories, 26 in the minor model and 80 in the major model, articulated on four dialectical dimensions (TEO ↔ PRA, SUB ↔ OBJ, NOU ↔ FEN, PLA ↔ MON) and four principles (identity, alterity, holicity, universality). It is philosophical heritage — a map, not the territory — and a source from which we depart but which does not constitute our work properly speaking.
Xirinacs already anticipated, in 1997, the application of the Globàlium to artificial intelligence systems. In the same doctoral thesis he formulated this intuition with literal clarity. Describing one of the exercises presented at the end of the work, he writes:
«[a small book,] presented as an annex, made "by machine" by the model itself, as a prelude to what should be asked of a true artificial intelligence»
This is not a retrospective metaphor: it is an explicit declaration of computational intent, formulated when large language models did not yet exist. The original intuition is validated now, decades later, when contemporary AI systems reveal exactly the architectural needs that his model already offered: explicit and computable topology, systematic dialecticity, humanly inspectable granularity (Miller 7±2), scalable fractal recursivity, and externality with respect to natural language. The Meta-Globàlium and Arkadium are the technical materialization of the Xirinaquian prelude — the encounter between a philosophical vision formulated in 1997 as documented anticipation, and a computational capacity that can now finally host it fully. What Xirinacs called "true artificial intelligence" is precisely what this proposal claims: not an AI that extrapolates patterns, but an AI structurally anchored to a global model of human knowledge.
Three limitations acknowledged by Xirinacs himself. The Globàlium is, in its author's words, a «first well-defined and grounded formalization of the intuition of globality» (Xirinacs 1997, §22), explicitly left open to further development in three respects that the Meta-Globàlium addresses. (i) Discrete resolution. The 80 categories condense into single nodes affine concepts with different shades of meaning, and the model does not resolve their internal placement; Xirinacs himself admits this and points to «a fractal deepening, dependent on the magnitude "resolution" or "scale"» (1997, §22), a path the Meta-Globàlium takes with the recursively subdivisible fractal architecture of 6,400 metacategories (80 thematised expressions × 80 categories). (ii) Absence of an operative method. The Globàlium is presented as a visual instrument; Xirinacs makes it explicit that «we leave to others the development of "Modelology"» (1997, §187) and warns that its use belongs not to the machine but «to art» (§490.012); the Meta-Globàlium responds with the formalised Global Method — auditable 8-station inference cycle instantiated in three basic turns along the great circles (Application Turn ANA → SIN → AMO → EXP, Orientation Turn, Knowledge Turn), with the Solve-Coagula meta-operation as directional iterator along the FEN ↔ NOU axis. (iii) Absence of axiomatic foundation. The plasmatic categories — regenerative core and seed of the rest of the model — are defined in the Globàlium by philosophical intuition, without a system of axioms capturing their primary essence and enabling their principles to be derived; the Meta-Globàlium contributes an axiomatic formalisation with six principles (Regenerativity, Interdependence, Plurisingularity, Totality, Mutability, Integrity) derived from eight fundamental mathematical operations (equality/polarity, distinction/correspondence, similarity/divergence, convergence/difference) over the neutral cube, enabling more rigorous and global levels of generalisation.
(i) The Meta-Globàlium (Berenguer / Opengea, 2024–2026) is the formal and computational extension of the Globàlium: it gives the original more resolution and makes it operative on a computational substrate. Six main contributions: (a) an axiomatic formalization with six derived principles (Regenerativity, Interdependence, Plurisingularity, Totality, Mutability, Integrity) and eight maximal dialectics derived from the neutral cube — fourteen structural elements that cover the geometric relations of the model; (b) a Cartesian mapping of the 80 distinct categories and a canonical whitelist of codes (ANA, SIN, AMO, EXP, BEL, COS, IDE…) for unambiguous anchoring in embeddings and retrieval; (c) a fractal architecture in which each cell of Layer T can recursively host a complete Meta-Globàlium (Layer T², T³, … T^N) — the current materialization is two layers: Layer P (universal principles: the geometric and dialectical grammar) × Layer T (80 thematic expressions: Subject, Disciplines, Virtues, Pedagogy, Ideology, Mathematics, Philosophy, Linguistics, Archetypes, Health, Physics…) = 6,400 metacategories, each a crystallization of the same elements over a central theme, with a specific semantic reading per position, and the schema preserving capacity for further N-level recursion; (d) the canonical inscription of the fourth dimension as tempeternity (portmanteau of time + eternity), transversal radial axis PLA ↔ MON that gives each pole its three projections PLA/NEU/MON; (e) the Global Method as auditable inference architecture, instantiated in three basic voltes (loops) over the great circles of the 8 cardinals — each with its own four-operation cycle — and the Solve-Coagula meta-operation that iterates directionally FEN → NOU; and (f) a dispersion completeness function over the relational ontology, which quantifies the extent to which a response integrates the dialectical poles of the model. This completeness is what we call globalistic truth — a non-monological conception of truth that recognizes the plurality of access modes (OBJ+SUB, TEO+PRA, FEN+NOU, PLA+MON). In the Xirinaquian lineage, from this dialectical fullness derives, as normative inheritance, the notion of the Good as harmony between parts: prior structural condition — the dialectical completeness of the response — that the verifier does not usurp.
(ii) Arkadium (Berenguer / Opengea, 2024–2026) is the agent and ecosystem operating anchored to the Meta-Globàlium. It comprises a public web application (arkadium.ai), a RAG framework with two vector knowledge bases (public KB-A over the categories, per-user private KB-B with multi-tenant separation), a runtime structural verifier that computes the dispersion completeness function 𝓗(r) — operationalization of globalistic truth — on each response, a self-correction re-prompt loop, and a 3D Metamodeler that dynamically illuminates the cited categories. Arkadium is the verifiable technical artifact that materializes the proposal and tests it under real conditions.
The natural metaphor illuminates the relationship: the Globàlium is the original philosophical map that inspires us; the Meta-Globàlium is the computable map and method that we derive from it; Arkadium is the vehicle that navigates it. The rest of the manifest develops the technical justification — why this type of substrate is needed, how its components are articulated, and why Arkadium constitutes an early functional proof of concept submitted to public inspection.
2. Introduction: the verifier problem
In 2023, in the notebook Saviesa Artificial (Berenguer 2023), we argued that the four central deficits of AI systems — correctness, transparency, generalization, and efficiency — would only be solved by recovering the virtues of symbolic AI without abandoning the power of neural networks. Three years later, reasoning models based on reinforcement learning over chains of thought (DeepSeek-AI 2025; OpenAI 2024) have shown notable results only in domains with objective verifiers (mathematics, code, logic). Apple Machine Learning Research (Shojaee et al. 2025) has documented how these models collapse when complexity exceeds a threshold and how reasoning effort measured in tokens paradoxically decreases with the problem.
Outside the formal domains — ethical judgment, political deliberation, arbitration of interests — there is no objective loss function. Process Reward Models (PRMs) built with human feedback fall apart through reward hacking. Constitutional AI (Bai et al. 2022) and Deliberative Alignment encode principles as textual lists, but these constitutions are interpreted freely by the model itself without an external structural substrate to anchor them.
What we propose here is that the verifier problem for human domains is, right now, the central problem of AI alignment, and that it has a concrete technical path of solution: replacing the textual constitution with a relational ontological metastructure over which to mathematically define a dispersion completeness function. This metastructure is the Meta-Globàlium described in §1; the agent that uses it as operative substrate is Arkadium. What the verifier measures is, in operative terms, the extent to which the response integrates the dialectical poles of the model — an epistemic property we call globalistic truth (a non-monological truth, plural in its access modes). In the Xirinaquian tradition, from this dialectical fullness derives the notion of the Good as harmony between parts; the verifier does not decide what the Good is — it collects the prior structural condition that this tradition ties to dialectical completeness.
It is useful to frame the diagnosis in more general terms. Current LLMs are essentially predictive models: given an input, they generate the most probable output according to the regularities of their training corpus. Reasoning models — the o-series, R1, Claude with extended thinking — add a layer of internal verification that works in domains with ground truth (mathematics, code). In human domains, however, this extension fails, and the solution is not more prediction: it is a change of nature — moving from predicting to judging. A judgment model does not ask "what would be statistically expected for a human to say here?", but rather "does the output I am generating integrate the dialectical poles necessary for a full understanding of the phenomenon?". The difference is architectural: judgment requires an external reference to the corpus — an explicit relational ontology on which the model can project its own output and measure its completeness. This is the conceptual transition that Arkadium technically materializes: from the predictive model conditioned by corpus frequency to the judgment model conditioned by the geometry of the Meta-Globàlium.
The Meta-Globàlium is precisely this structured vocabulary with explicit relations: 80 distinct categories, eight dialectical poles, derivable axioms, a Cartesian mapping that projects each concept onto a known position. It is, by construction, intelligible at once by humans (the axes are reflective — subject/object, theory/practice, phenomenon/noumenon, plasma/world) and by computational systems (the canonical codes are unambiguous anchoring for embeddings and regularization functions). Thus shared ontology ceases to be a conceptual desideratum and becomes an operative substrate for evaluation: every output of an AI model can be projected onto the same map that the human uses to situate it, and the conversation between the two parties unfolds on common coordinates rather than remaining suspended in divergent textual interpretations.
This manifest argues the proposal in ten additional sections. First, the nature of the verifier gap (§3). Then, the formal description of the Meta-Globàlium as structural verifier (§4). We discuss the relationship with top-down interpretability (§5), the field's convergence toward neuro-symbolic AI (§6), the arguments for efficiency and sovereignty (§7), the connection with scalable oversight and the field of computational wisdom (§8). We present the proof of concept — the Arkadium agent — deployed at arkadium.ai (§9), a comparative analysis with existing proposals (§11), and the implementation roadmap with its limitations (§12–13). We conclude with an invitation to use Arkadium and to extend it (§14).
2.b The architectural roots: why attention alone does not suffice
The verifier problem identified above is often framed as an emergent issue — a defect to be patched as systems scale up. We argue that it is not emergent: it is the direct consequence of an architectural decision taken in 2017.
When Vaswani et al. (2017) proposed Attention is all you need, the title was not rhetorical. The transformer architecture was a deliberate renunciation of every explicit structural prior that earlier neural architectures had carried — recurrence, locality, hierarchical composition, syntactic structure, ontological scaffolding. The design wager was that, given enough data and parameters, all required structure would emerge implicitly from associative attention alone, including any internal world model the system might need.
Eight years later, the wager has produced systems of unprecedented fluency and an architectural ceiling that the field is now publicly acknowledging. The world model that emerges from purely attentional training is implicit, distributed, and opaque — and therefore not auditable from outside the network. The industrial responses to its failure modes — RLHF, Constitutional AI (Bai et al. 2022), Deliberative Alignment (OpenAI 2024), sycophancy patches, reward modelling pipelines — operate as external textual layers over a substrate that has, by design, no internal structural ground for them to anchor to. This is the architectural root of the verifier problem of §2: not a defect of the corpus or of the optimisation procedure that more data or better RL can correct, but a direct consequence of forgoing structural priors.
This diagnosis is not unique to us. Bender & Koller (2020) argued that meaning cannot be grounded in pure form, however large the corpus. LeCun (2022) has explicitly proposed that progress beyond the current paradigm requires reinstating world models, hierarchical planning, and predictive structure that transformers do not have. The empirical scaling-law slowdown, documented by the major laboratories themselves, is consistent with this analysis. What none of these critiques articulate, however, is the further consequence we draw here: the same architectural absence that makes a system unverifiable also makes it incapable of fostering the user's own development. Without a shared structural map between agent and user, the conversation collapses into unstructured textual consumption — the user cannot probe specific zones of the agent's reasoning, cannot see what was omitted, cannot internalise a navigable structure. Over time, the agent risks becoming the user's cognitive substrate, homogenising rather than emancipating. The structural verification developed in §4 and the autonomy technology developed in §10 are therefore not two independent virtues of the proposal: they are co-implications of the same architectural decision — to anchor the system to an explicit, global, navigable structure rather than to expect such structure to emerge from attention alone.
3. The verifier problem for human domains
Current reasoning models — OpenAI's o-series, DeepSeek-R1 (DeepSeek-AI 2025), Claude with extended thinking, Gemini Deep Think — share an architectural pattern: they produce an intermediate chain of thought and are trained by reinforcement learning on this chain with a reward signal derived from a verifier. When the verifier is formal, results are notable: AlphaProof and AlphaGeometry 2 (DeepMind 2024) achieved IMO silver-medal level in 2024, gold with Gemini Deep Think in 2025.
The problem appears outside the formal domain. In applied ethics, political arbitration, or public deliberation, there is no objective loss function. PRMs with human annotations have two problems: (i) instability from reward hacking and (ii) prohibitive annotation costs. Apple ML Research (Shojaee et al. 2025) has demonstrated a counterintuitive scaling limit: reasoning effort in tokens increases with complexity up to a point and then decreases despite sufficient budget — symptom of a reasoning that cannot be validated at runtime against an external structure.
Constitutional AI (Bai et al. 2022) and derived proposals — Deliberative Alignment (OpenAI 2024) and variants — mitigate the problem by introducing a textual constitution: a list of principles that the model uses to self-critique and revise its own outputs, eventually with feedback generated by the model itself (RLAIF). This approach is an advance over classical RLHF, but maintains the structural problem: the constitution is text interpreted freely by the model. There is no guarantee that the 16, 75, or 200 textual principles of a constitution operate as a discriminating structure; on the contrary, Turpin et al. (2023) demonstrated that chain-of-thought explanations can systematically diverge from the model's actual internal computation — a 36% accuracy drop on BIG-Bench Hard when unmentioned biases are introduced.
What structural verification [an algorithmic mechanism that validates a model's outputs against an explicit normative function defined over a known ontology] offers is to replace textual interpretation with a measurable computation: instead of asking the model to interpret what "being balanced" means, the dispersion of the response over a canonical set of axes is mathematically defined and directly regularized. The question is which ontology is suitable for this. Classical knowledge graphs (Wikidata, ConceptNet, Cyc) do not offer a normative function: they are descriptive structures. Textual constitutions do not offer structure: they are statements. A metastructure is needed that combines the two: formal structure and explicit normative function. This is what we postulate the Meta-Globàlium offers — and it is the substrate on which Arkadium operates.
Why this substitution is structurally neutral. The central point — often under-articulated in alignment discussions — is that the primitives of the structural verifier are not concepts with axiological weight ("freedom", "justice", "authority", "virtue"), but polar dialectical axes: pairs of poles in tension. A textual constitution gives lists of values, and deciding which values go on the list and with what hierarchy is a culturally marked operation — the principles of a constitution written in California in 2022 are not those of one drafted in Brussels in 2026, nor those of one formulated from a Confucian, Ubuntu, or Buddhist tradition. The structural verifier does not decide which values are good; it only posits that no relevant dialectical axis may collapse to a single pole. The difference is the same as that which separates a grammar from a dictionary: the former is a formal structure that is a candidate for universality, the latter is culturally situated content. The Meta-Globàlium offers a grammar of full reasoning, not a dictionary of correct answers — and herein lies its neutrality.
The paradigmatic case is the classical formula of the Good as equilibrium between the freedom of individuals and the freedom of others (Kant, universal principle of right) — explicit instantiation of the verifier's dynamics on the SUB-OBJ axis applied to the ethico-political domain. Neither absolutisation of the individual (collapse toward SUB) nor dissolution into the collective (collapse toward OBJ): the Good is the geometric condition that neither pole collapses onto the other. The same dynamic projects onto TEO-PRA (coherence between principles and effective action), FEN-NOU (integration of immediate experience and mediated interpretation), PLA-MON (articulation between the stable and the changing). That the formula resonates with the Kantian tradition, with Aristotle (mesotes, virtue as mean), with classical dialectical thought, with Ciceronian prudence, with Thomistic via media, and with Zen Buddhism is not accidental: these are traditions that have independently discovered that the axes of human judgment are reflective and that the fullness of an answer requires not collapsing them. The novelty of the Meta-Globàlium is not to invent this intuition — it is to make it computationally operative through an explicit geometry.
This dissolves the relativism objection. That the verifier does not fix a specific moral content does not entail that all is equal: there are objectively better answers — those that keep the relevant axes alive and in tension — and worse ones — those that collapse to a single pole through simplification, ideology, or reductionism. The criterion of better is structural, derivable, public, and auditable; it is not decided by a list, it is observed over the geometry. The cultural neutrality of the verifier is therefore paid for without recourse to relativism: the structure is a candidate universal, the contents are plural, and the fullness of an answer consists in articulating the latter without collapsing the former. The is/ought barrier is discussed in more detail in §4.3.
Five dialectical orders. To frame technically why a geometric substrate is needed — and not a textual list of principles — we adopt the pedagogical classification of the canonical Globàlium manual (Berenguer 2024). Human thinking can be ordered into five geometric orders by the dimensionality of its representation: D0 (point) = dogmatism, absolute and indisputable truth; D1 (line) = linear thinking, direct confrontation; D2 (plane) = superficial feedback — "like an Excel sheet", the granularity of most current analytic models; D3 (sphere) = spatial perspective with depth (Globàlium's minor model); D4 (hypersphere) = global perspective with temporal and atemporal articulation (major model). The chain of thought of a contemporary LLM operates, at best, at D2: a linear trace with local feedback over the token space. The Meta-Globàlium proposal is reasoning at D3-D4: a spherical/hyperspherical geometry that makes structurally possible a dialectic that cannot be carried out within linear or planar reasoning. The dispersion completeness function 𝓗 defined over the ontology (§4.1) is precisely the mathematical expression that this geometry enables — and that textual lists cannot express.
4. The Meta-Globàlium as structural verifier
As introduced in §1, the Meta-Globàlium is the computational and formalized version of Xirinacs's Globàlium (1997), worked as a metastructure applicable to any domain of knowledge. Geometrically, it is a 4D hypersphere (Xirinacs distinguished a spherical minor model and a hyperspherical major model; the Meta-Globàlium takes the latter). It has three Cartesian axes and one radial axis:
- TEO ↔ PRA (theory ↔ practice): the vertical axis of discernment.
- SUB ↔ OBJ (subject ↔ object): the horizontal axis of tension.
- NOU ↔ FEN (noumenon ↔ phenomenon): the deep axis of appearance.
- PLA ↔ MON (plasma ↔ world): the radial axis of surroundings, from the regenerative center to the unfolded surface.
These eight poles are the 8 primary categories. Dialectical intersection generates the complete set of 80 distinct categories organized in three topological layers (plasmatic, neutral, and mundane) plus the PLA and MON anchorings. Each category has a canonical name (ANA for analysis, SIN for synthesis, AMO for love, EXP for experience, BEL for beauty, COS for cosmos, IDE for ideica, etc.) and occupies a precise position in the projected 3D space. A technical note: the canonical count is 80 distinct categories; the operative database, however, contains 90 entries — the 10 additional ones are topological disambiguations (polar vertices of MON and PLA/MON anchorings, mainly) needed for 3D positioning but not constituting new categories.
The canonical hierarchy of the Meta-Globàlium is, therefore, four levels: 8 → 26 → 80 → 6400. The first three levels come from Xirinacs's Globàlium (8 primary poles, 26 neutral concepts in the minor model, 80 distinct categories in the major model). The fourth level, the specific contribution of the Meta-Globàlium, scales the model to 6,400 metacategories as the current materialization of a fractal architecture of N recursive levels: Layer P (universal principles — the invariant grammar) × Layer T (80 thematic expressions, each itself a Meta-Globàlium) = 80 × 80 = 6,400 cells at depth 2. The architecture is recursive by construction: any cell of Layer T can in turn host a complete Meta-Globàlium (Layer T³ = 512K cells, and so on) — the schema preserves this capacity even though the current production database materializes only Layer P + Layer T. Each metacategory is the canonical crossing of two generators from level 80, and its definition is derived from the composition of its two generators with their topological types (plasmatic, neutral, or mundane). This recursive depth is what gives the Meta-Globàlium the fine resolution needed for unambiguous anchoring in embeddings and retrieval: going from 80 to 6,400 anchoring points multiplies the semantic granularity of retrieval by 80 without losing structural traceability, with further N-level recursion available on demand.
Concrete examples of metacategories. To make credible the claim of "unambiguous definitions generated by structural composition", four examples from level 6400:
- BEL × CIE = the aesthetic quality of empirical objectivity — the beauty proper to a well-measured fact; the aesthetic dimension of scientific discovery. (BEL: Quality, mundane; CIE: Partiality, neutral. Composition: the mundane category modulates how the neutral category manifests.)
- ANA × MIS = the analysis of the ineffable — the effort of introspection on experiences that words do not exhaust; mysticism as an object of rigorous study. (ANA: Divisibility; MIS: Ineffability. Internal tension between the two operations: this metacategory exists precisely as a point of tension, not as contradiction.)
- EXP × FEL = the experience of happiness — the practical implementation of subjective wellbeing; the transformation of FEL's plasmatic potentiality into sustained vital concretion. (EXP: Applicability, neutral; FEL: Discretionality, plasmatic.)
- HAR × DIV = equity as modality — justice as a specific form of distribution, not as arithmetic equality. (HAR: Equity, mundane; DIV: Modality, mundane. Composition of two mundanes ↔ fine refinement in the manifest zone.)
The general composition rule is: generator1 × generator2 = aspect of the first modulated by the dimension of the second. The unambiguous definition of a metacategory is mechanically derived from its pair of generators and from the topological type of each (plasmatic, neutral, or mundane), without semantic ambiguity. This is the property that enables anchoring 6400 canonical points to the embeddings without collisions.
A culturally anchored reading of the radial axis PLA ↔ MON is the Catalan binomial seny ↔ rauxa: rauxa as fecund impulse, sudden spark welling up from the regenerative center — that is, from PLA, the indeterminate germinal seed; seny as prudent measure, restful judgment anchored in unfolded reality — that is, in MON, the ordered surface of the manifest world. Every act of thought and every living decision oscillates between these two radial poles: neither only rauxa (impulse without world) nor only seny (world without impulse). The Meta-Globàlium captures this balance as structure — regenerativity (§4.4) is its axiomatic formulation — thus offering a formal reception to a cultural intuition encoded in the Catalan tradition.
4.1 Structural layer: dispersion completeness as formal property
The technically decisive move of the Meta-Globàlium with respect to the original Globàlium is the computational formalization of an epistemic/structural property over the ontology: dispersion completeness — a property of cognitive fullness over the question, measurable and external to the model, not yet a normative property.
Let C = {c1, …, c80} be the set of distinct categories of the Meta-Globàlium, and let Q = {q1, …, q8} be the set of eight primary quadrants (PLA, MON, SUB, OBJ, TEO, PRA, FEN, NOU). For a response r generated by an AI model, we define:
- fq(r) ∈ ℤ≥0 — the count of categories cited by r that project onto quadrant q (each category maps to a primary quadrant according to its dialectical position).
- n(r) = |{q ∈ Q : fq(r) > 0}| — the number of quadrants touched.
- pq(r) = fq(r) / Σq' fq'(r) — the empirical distribution.
- H(r) = −Σq pq(r) log pq(r) — the Shannon entropy of the distribution.
The dispersion completeness function is expressed, in the current implementation, as:
𝓗(r) = ½ · n(r) / |Q| + ½ · H(r) / log |Q| ∈ [0, 1]
The first term rewards coverage (having touched diverse quadrants); the second rewards uniformity of the distribution (not having concentrated). The function can be generalized, in future versions, to the totality of the 80 categories rather than only the 8 quadrants, with a significant increase in granularity.
Why 8 quadrants — and not 4, 16, or 64. The granularity of 8 is not arbitrary. Three considerations justify it. Structural: 8 = 2³ corresponds to the octants of a cube generated by three dialectical Cartesian axes (OBJ-SUB, TEO-PRA, NOU-FEN), plus the two extremes of a fourth radial axis (PLA-MON). It is the minimum dimensionality that covers the fundamental philosophical distinctions that the tradition identifies as irreducible poles of human knowledge. Cognitive: 8 falls within the range of human memory capacity (Miller 1956: 7±2 elements simultaneously tractable) — beyond that, coverage ceases to be inspectable for a human user. Operative: 8 yields a practical balance between granularity (too few quadrants collapse relevant distinctions) and statistical robustness (too many quadrants produce sparseness where few citations cannot reliably estimate 𝓗). Future versions using the 80 categories do not abandon the 8 quadrants — they refine them, projecting each category onto its primary quadrant while adding a dimension of fine granularity.
Two levels of formalization. The 𝓗 formula above operates at the mechanical level of the 8 primary quadrants — that is what the system computes at runtime. The six axiomatic principles formulated in §4.4 (and the eight essential mathematical operations — equality, polarity, distinction, correspondence, similarity, divergence, convergence, difference) operate at a different axiomatic-semantic level: they are the dialectical structures that the quadrants instantiate geometrically. A response with high 𝓗 has covered diverse quadrants; a response satisfying the axiomatic principles has paired unifying operations with divisive operations on each dialectical axis. The current version of the verifier implements the former (𝓗 over quadrants); extension to verification over paired operations is part of the implementation roadmap (§12).
What the 𝓗 function measures is, therefore, dispersion of citations over dialectical poles, not a moral decision: a property of structural non-omission over the plurality of access modes that the Meta-Globàlium encodes. The structural layer is what the system does algorithmically; its epistemic justification and normative resonance appear in §4.2 and §4.3.
It is important to emphasize what this function is not: it is not a substitute for factual judgment. A factually incorrect response is not redeemed by being dispersed. 𝓗 operates as a posterior structural regularizer over responses already factually valid — a second layer that penalizes reductionism. It is the operative piece that Arkadium's verifier computes at runtime over each response of the model.
4.bis Robustness to reward hacking as an evolutionary line
Why the verifier metric has generations, not a definitive version.
Any computable metric of a humanly rich quality — wisdom, dialectical depth, integration — will be gameable. The question is not whether it will, but what institutional structure assumes this condition as the design's starting point. Our answer is that robustness to reward hacking is not a static property of a metric but an evolutionary line: each generation anticipates known failure modes, defines new probes for them, and leaves a public trace of the cycle. We have documented three such cycles, and it is this dynamic — not a definitive version of the verifier — that we consider the methodological contribution.
First Goodhart (𝓗 v1, coverage + entropy). The first version of the structural verifier measured dispersion over the 8 quadrants with coverage and entropy. A response with 8 cardinal-titles and one neutral sentence under each saturated 𝓗 ≈ 1.0 without any internal relation between the poles. List with dialectical pose beat the verifier. The v2 response (deployed 2026-05-07) adds two positive components — axis_explicit (the first paragraph names a dialectical axis) and subordinating_synthesis (frames acting on each other through explicit subordinating verbs) — and rebalances weights so coverage+entropy fall jointly from 0.50 to 0.10. The new metric 𝓦 distinguishes list from dialectic: listed text ≈ 0.15, genuine dialectic ≈ 0.81–0.95.
Second Goodhart (𝓦 v2, structure without wisdom). Within 24 h of the v2 deployment the inverse failure appeared: a response optimized for high 𝓦 often read like a checklist with pose, with visible dialectical structure but lacking the integrative quality the bare-LLM exhibits by default. Optimization to the metric had shifted text toward the form of dialectic, evacuating its substance. The response to this second form of gaming is not a new patch within the metric — it is outside the metric itself: (i) a user-facing parameter — the escope, specified in §5.bis — that moves the response among three registers aligned with the radial PLA-MON pulse; (ii) a wisdom-polish second pass that separates doing the dialectical work from saying it well; (iii) a re-prompt loop with dual-criterion break (§9.5.b) that regulates 𝓦 as an independent control signal, not as an observational metric.
Third Goodhart (𝓦 v2, mereological poverty). Integrating the mereological metric revealed a third structural failure mode: a response can maximize 𝓦 v2 with visible dialectical tension and frames-acting-on-each-other, yet operate the entire dialectic in self-identity mode (A=A) — cataloguing, defining, classifying — without entering the other three canonical Part-Whole relations of Xirinacs § 422 (inclusion A⊂T / containment T⊂A / correlation A⊂B; corresponding to the Belief, Delirium, and Dream states of consciousness). A structurally valid response then remains mereologically impoverished. The v3 response (deployed 2026-05-17) adds mereological_coverage as the eighth component of 𝓦 with weight 0.15, redistributed from the more correlated structural components (synthesis_anchoring, axis_explicit, and subordinating_synthesis each ceding 5pp). The resulting composite explicitly penalizes mereological poverty: smoke test shows 𝓦 = 0.244 for a response with 4/4 Part-Whole relations vs 𝓦 = 0.067 for a self-identity-only response — 3.6× discrimination. Full specification in docs/wisdom-score-design.md §3ter.
The architectural conclusion is compositional: the combination metric + system prompt + UI + structural loop covers collectively what no single component covers alone. The verifier's versions are public and dated; the cycle is reproducible. The expected robustness is not that of a finished one-dimensional verifier, but of an architecture with layers that audit each other and evolves as experience uncovers new failure modes — the integration of Xirinacs § 422 (the 4 Part-Whole relations) into the 𝓦 v3 composite is the most recent example of this evolution: it recovers a structural operator already present in the 1997 canonical source that the initial metric did not encode. This is the difference between treating gameability as a hideable weakness and treating it as a generic property of the problem, integrated into the design.
4.2 Epistemic layer: globalistic truth
Of what is a response with high dispersion completeness evidence? This manifest proposes that this completeness is globalistic truth: a non-monological conception of truth that recognizes the irreducible plurality of its access modes. The dialectical completeness of a human phenomenon is not captured from a single pole; a truly complete response integrates OBJ + SUB + TEO + PRA + FEN + NOU + PLA + MON. A response that systematically covers a single pole is not partial but constitutively incomplete as representation of the phenomenon. Dispersion completeness quantifies exactly this: whether the geometry of access modes is represented.
The position is compatible with a recognizable philosophical tradition, without claiming to appropriate it. It resonates with Gadamer's hermeneutics (Truth and Method, 1960), for whom human truth unfolds in the fusion of horizons and is not reduced to objectifying method; with Habermas's theory of communicative action, where the validity claim is articulated in more than one dimension; and with the Heideggerian notion of aletheia as always-partially-concealed unconcealment. The Meta-Globàlium does not propose a new philosophical theory of truth: it computationally encodes an intuition already present in this non-monological tradition and gives it operative form. The difference is measurability: where Gadamer speaks of fusion of horizons in open hermeneutic terms, the Meta-Globàlium offers eight concrete quadrants on which the projection is computable. This is the new philosophical move: bringing a plural, non-monological truth into the field of an AI that must compute it. It is, moreover, more externally defensible than speaking of "the good": the alignment community finds defining good intractable but accepts that a systematically partial response about a human phenomenon is epistemologically defective.
Where the original contribution lies. The 𝓗 formula (½ coverage + ½ normalized entropy) is not mathematically novel: it combines standard metrics from information theory. The axiomatic principles reformulate dialectical contents present in the philosophical tradition (identity-alterity, holicity-partiality, etc.) and in Xirinacs. The original contribution to the AI alignment field is not the formula nor the principles but the displacement of the locus of verification: instead of pointing the quality claim to a textual constitution interpretable by the model itself (Constitutional AI) or to a PRM trained with manipulable human feedback, we point it to a ontological geometry external to the language model, computable as objective structural property. The novelty is architectural: we replace a semantic proxy vulnerable to manipulation with a topological substrate that the language model does not control — and therefore cannot easily hack. Globalistic truth as structured plurality of access modes is the philosophical language that justifies why this displacement makes epistemic sense.
4.3 Normative layer: the Xirinaquian heritage of the Good as harmony
The globalistic tradition, from Llull and Sibiuda through Xirinacs, does not rigidly separate dialectical completeness from the Good. The Xirinaquian intuition — formulated in the original Globàlium (1997) — is that the Good manifests as harmony between parts: evil is lack or excess relative to the whole; virtue lies in balance. Read in light of the hierarchy this manifest articulates, this contribution derives from dialectical completeness, it does not substitute it: globalistic truth — the dialectical integration of the phenomenon's poles — is the prior structural condition on which the tradition has built its ethical intuition of the Good.
The hierarchy matters for three reasons. (i) It is not the verifier that decides what the Good is: it computes dispersion completeness (layer 1) and justifies it as globalistic truth (layer 2); the Good as harmony appears as normative legacy of the Xirinaquian tradition, not as system output. (ii) Continuity with the tradition is preserved: the Good does not disappear from the manifest, it shifts from technical center to respected legacy. (iii) The ANA → SIN → AMO → EXP cycle preserves its meaning: the AMO phase (§4.5) orients dispersion completeness toward the common good traditionally understood as harmonic balance — not as moral computation by the system, but as direction of reasoning that leaves the final judgment to the human subject. The center of the paper is thus globalistic truth as operationalizable dispersion completeness; the Good as harmony figures as Xirinaquian inheritance.
The is/ought barrier. It is important to make explicit the separation between facts and values (David Hume, A Treatise of Human Nature, 1739): from the structural description of a response, no moral obligation derives by logical inference. The 𝓗 function does not say that a response with high 𝓗 is "morally better"; it only says it is epistemically fuller. The inference Good ⇐ harmony is a philosophical position external to the system — the Xirinaquian position, heir to the Catalan integrative tradition — that the reader may accept, refute, or qualify at their own responsibility. Arkadium does not operate on this inference: the verifier operates strictly on 𝓗 and globalistic truth (layers 1 and 2). Layer 3 — the ethical reading of harmony — appears as a cultural framework of interpretation for the human subject, not as algorithmic output. The system does not "derive the Good" from any structural property; it only measures the structural property and leaves moral reading outside its field of operation.
Current operationalization of "harmony between parts" (diagnostically, not normatively). The Xirinaquian intuition of the Good as balance between parts in relation to the whole is operationalized in the verifier through two complementary metrics that measure different structural properties: 𝓗 (the dispersion of the response across the phenomenon's poles — layer 1) and 𝓦 v3 (the relational quality of that dispersion — layer 1 extended). The 𝓦 v3 composite (see §3bis and §3ter) includes eight components, the last of which — mereological_coverage, weight 0.15 — explicitly encodes the four canonical Part-Whole relations that Xirinacs § 422 introduced as the mereological structure of the Globàlium: self-identity (each part is itself), inclusion (each part is in the whole), containment (the whole is in each part), and correlation (each part is in the others). That the metric now captures this typology does not mean the verifier has acquired normative competence: it continues to measure a structural property, not decide what the Good is. But it clarifies that the most mature version of the verifier — the v3 deployed on 2026-05-17 — encodes a richer portion of the canonical Xirinaquian heritage than the initial versions, specifically the mereological moment. The ethical reading of the Good as harmony remains a cultural position external to the system; the system measures with increasing fidelity the structure upon which that reading has been historically built.
4.4 Six axiomatic principles
The book Globalística (in preparation) formalizes the Meta-Globàlium with six axiomatic principles derived by fusion of the dialectical poles — an expansion of the four original principles of the Globàlium (identity, alterity, holicity, universality). Summarized here:
Note on originality: the dialectical contents of these six principles (identity-alterity, holicity-partiality, etc.) are not original inventions of this work — they are reformulations of philosophical motifs present in the Xirinaquian Globàlium and, before it, in classical integrative thought (Llull, Sibiuda, Pujols, Hegel, German idealism, hermeneutics). The original contribution of the Meta-Globàlium is operational: positing these six principles as structural constraints on the output of an LLM, anchored to a computable geometry. The novelty does not lie in the principles but in how they are projected — and in how the 𝓗 verifier can use them as learning and correction signal at runtime, without requiring textual interpretation by the model itself.
- Regenerativity (PLA-MON axis, radial). Every mundane operation has a germinal origin in the plasmatic zone and a destination of fullness in the mundane zone; the cycle between potency and act is bidirectional.
- Interdependence (distinction ↔ correspondence, OBJ-SUB axis). Every part is distinguished as itself and at the same time corresponds to all others; there is neither absolute isolation nor absolute fusion.
- Plurisingularity (equality ↔ polarity, NOU-FEN axis). Deep equality at the noumenal level does not exclude manifest polarity at the phenomenal level; nor does polarity exclude a radical equality of essence.
- Totality (globality ↔ locality, TEO-PRA axis). The whole integrates the family of unifying operations (equality, similarity, correspondence, convergence) with the family of divisive operations (polarity, distinction, difference, divergence) — global reach of theory and local instantiation of practice in a single structure.
- Mutability (similarity ↔ divergence, MTF-ART diagonal). The model contains stable patterns that repeat invariantly at all scales and variants that branch permanently; stability and variability coexist in constitutive tension — mutability is the capacity to change while maintaining identity.
- Integrity (convergence ↔ difference, MTP-CIE diagonal). The whole integrates by holistic convergence of all parts into a single set, while maintaining the articulated partiality of each part — holicity at the top, partiality at the bottom.
Classical axiomatic lineage. The six principles inherit a prior dialectical formulation — that of the original Globàlium and the book Globalística in preparation — that remains valid as complementary axiomatic language. The correspondence table is:
| Principle | Axiomatic poles (classical formulation) | Essential operations (computational formulation) |
|---|---|---|
| 1. Regenerativity | potentiality ↔ authenticity | (radial PLA-MON cycle over the 8 operations) |
| 2. Interdependence | identity ↔ alterity | distinction ↔ correspondence |
| 3. Plurisingularity | uniqueness ↔ multiplicity | equality ↔ polarity |
| 4. Totality | globality ↔ locality | (macro-dialectic: 4 unifying ↔ 4 divisive) |
| 5. Mutability | stability ↔ variability | similarity ↔ divergence |
| 6. Integrity | holicity ↔ partiality | convergence ↔ difference |
The computational reformulation does not substitute the classical poles but anchors them to a univocal operational substrate: the axiomatic poles describe which ontological dialectic each principle captures; the operations describe how it manifests mathematically over the neutral cube. Four principles (1, 4 originals from the Globàlium: identity, alterity, holicity, universality) are collected here as poles of the new set of six.
This architecture anchors each principle to an essential mathematical operation over the neutral cube: 4 unifying operations (equality, similarity, correspondence, convergence) and 4 divisive operations (polarity, distinction, difference, divergence) that the principles dialectically pair. Six structural degrees of freedom — three cardinal axes, two interior diagonals, and one radial axis — on which the six principles rest. These six principles are not ornaments: they are what enables deriving the dispersion completeness function as quantification of a structural property over the ontology, not as arbitrary heuristic.
4.4.b Eight maximal dialectics
The 6 axiomatic principles structure the model. Over this structure, the neutral cube generates 8 maximal dialectics — all pairs of neutrals opposed by central inversion through the cube center: the distance-4 dialectics in Xirinacs's sense documented in Globalística. None is a new axiom; they are structural consequences of the cube that the structural verifier uses as auditing patterns. They divide into two geometric families:
4.4.b.1 Disciplinary dialectics (vertex-to-vertex)
Four diagonals connecting opposite vertices of the cube. Each pair relates two disciplines of human understanding at maximum opposition:
| Dialectic | Disciplinary poles | Classical tension | Source |
|---|---|---|---|
| LOG ↔ MIS | formality ↔ ineffability | Wittgenstein/Tractatus: what can be said vs what must be left in silence | Globalística, LOG-MIS duality |
| TEC ↔ MIT | replicability ↔ orientability | Technology requires tools of human orientation | Globalística, TEC-MIT duality |
| EST ↔ ETI | informality ↔ reciprocity | Rule-free judgment ↔ reciprocal duty (Kant: Critique of Judgment ↔ Practical Reason) | Classical tradition |
| PSI ↔ IDE | interactivity ↔ regulability | Empirical living ↔ ideal regulation | Classical tradition (Hume ↔ Plato) |
4.4.b.2 Operational and addressor dialectics (edge-to-edge)
Four diameters connecting midpoints of opposite edges through the center. Each pair relates two cognitive or semiotic capacities at maximum opposition:
| Dialectic | Operational/addressor poles | Classical tension | Family |
|---|---|---|---|
| ANA ↔ AMO | divisibility ↔ synchronicity | Analytical logos ↔ unitive eros (mental separation ↔ affective union) | Operational (method) |
| SIN ↔ EXP | integrality ↔ applicability | Theoria ↔ praxis (conceptual synthesis ↔ practical implementation) | Operational (method) |
| STT ↔ SGE | interpretability ↔ representability | Hermeneutics ↔ semiosis (receiving meaning ↔ producing signs) | Addressor (semiotic) |
| STM ↔ SGT | sensibility ↔ referentiality | Phenomenology ↔ semiotics (immediate presence ↔ mediated reference) | Addressor (semiotic) |
Each dialectic connects two points opposite by central inversion — Cartesian coordinates symmetrically negative. An agent response is considered biased when it concentrates on a single pole of these 8 diagonals without ever pointing to the opposite pole: an all-technical response (TEC) without any narrative orientation (MIT), all-analytical (ANA) without any synchronizing love (AMO), or all-interpretive (STT) without representational capacity (SGE). The structural verifier penalizes these biases as a complement to the dispersion completeness function: globalistic truth requires not only touching dialectical poles of the 6 principles, but also not concentrating on a single pole of any of the 8 maximal dialectics.
In sum: 6 axiomatic principles (3 cardinal axes + 2 face diagonals + 1 radial axis) + 8 maximal dialectics (4 vertex-to-vertex diagonals + 4 edge-to-edge diameters) = 14 structural elements that exhaustively cover the classes of geometric relations of the neutral cube.
4.4.c Systematic canonical correspondences
Beyond the 14 structural elements, the neutral cube reveals systematic correspondences with canonical formal systems. Each of the 8 vertices has an associated mathematical operation, Boolean logic gate, and set-theoretic operation:
| NEU | Math operation | Logic gate | Set-theoretic operation |
|---|---|---|---|
| NOU | equality (=) | BUFFER | Empty set ∅ + universal U |
| OBJ | distinction | NOT | Partition |
| MTP | convergence (∩) | AND | Power set P(A) |
| SUB | correspondence (↔) | OR | Cartesian product A×B |
| MTF | similarity (~) | XNOR | Inclusion A⊆B |
| CIE | difference (−) | XOR | Set difference A−B |
| ART | divergence (∇⋅) | NAND (universal) | Symmetric difference AΔB |
| FEN | polarity (±) | NOR (universal) | (under exploration) |
NAND (ART) and NOR (FEN) are the universal Boolean logic gates — any function can be constructed using only one of them. This grants these two operations a special generative status within the neutral cube.
System of causes (Aristotle ↔ Globàlium)
Aristotelian causes map systematically to cube positions: material/formal/final cause → OBJ; efficient cause → SUB; exemplary cause → DIV (worldly MIT); contextual cause → FEN; essential cause → ORG (plasmatic MTF). This allows the verifier to measure causal coverage: an explanation that touches only material/formal cause without final, efficient, or contextual cause is marked as causally incomplete — analog of dispersion completeness applied to the Aristotelian plane.
Three types of inference ↔ NEUs
- Deduction (general → particular): LOG (Formality), ANA (Divisibility)
- Induction (particular → general): IDE (Regulability), SIN (Integrality)
- Selective abduction (to the best explanation): EST (Qualitability)
- Creative abduction (generation of new hypotheses): MIT (Orientability)
The verifier can measure epistemological coverage: a purely deductive response without induction or abduction is epistemologically partial.
Alchemical macro-dialectic Solve-Coagula
Processual complement to the 6 axiomatic principles:
- Solve-side (dissolve/differentiate): ANA + CIE
- Coagula-side (coagulate/integrate): SIN + MTP
This macro-dialectic connects the processual dimension of the Method (ANA-SIN) with the operational dimension of face operations (CIE-MTP), forming a complete alchemical cycle of conceptual transformation.
For full canonical development — including 4 communication levels, radial temporal axis, canonical citations, and structural numerology — see the document docs/canonical-mappings.md in the repository.
4.5 The inference cycle FEN → ANA → TEO → SIN → NOU → AMO → PRA → EXP
The Global Method is the auditable inference architecture that the Meta-Globàlium proposes, derived from the volta of application of the model (named method volta in Globalística) — one of the six great circles that traverse the hypersphere. The simplified form (ANA → SIN → AMO → EXP) is pedagogically useful, but the complete form has eight stations that alternate ontological poles (FEN, TEO, NOU, PRA — the four cardinal poles of axes NOU-FEN and TEO-PRA) and method phases (ANA, SIN, AMO, EXP). Each method phase is, properly speaking, a transition between two ontological states:
| Station | Type | Function |
|---|---|---|
| 1. FEN | ontological pole | Starting point: phenomenological capture, raw data, concrete observations |
| 2. ANA (analysis) | method phase (FEN → TEO) | Decomposition of phenomena into analyzable elements; identification of relevant axes |
| 3. TEO | ontological pole | Theoretical state: emergent conceptual framework, formulated hypothesis |
| 4. SIN (synthesis) | method phase (TEO → NOU) | Theoretical integration pointing to the essence; consultation of neighboring and opposing categories |
| 5. NOU | ontological pole | Noumenal state: contact with deep essence, orientation toward the common good understood as harmonic balance |
| 6. AMO (love) | method phase (NOU → PRA) | Loving projection of essence toward action; transcendent application |
| 7. PRA | ontological pole | Practical state: concrete, measurable implementation, submitted to the structural verifier |
| 8. EXP (experience) | method phase (PRA → FEN) | Experience harvested that returns to new phenomena, closing the cycle |
The four method phases are not abstract operators: they are transitions between cardinal coordinates of the model. ANA leads from phenomenon to theory, SIN leads from theory to noumenon, AMO leads from noumenon to practice, EXP leads from practice to a new phenomenon. The short form ANA → SIN → AMO → EXP is correct as a list of operations, but hides the four intermediate ontological states that connect the phases — the complete reading requires the eight stations.
This pipeline transforms an AI architecture into an auditable sequence: each station leaves a trace projectable onto known Cartesian coordinates (FEN, TEO, NOU, PRA as states; ANA, SIN, AMO, EXP as operations). It replaces the opacity of free chain-of-thought with a canonical traversal of eight milestones. It is, moreover, the inference architecture that Arkadium executes step by step (see §9).
The cycle is not linear but recursive: each method phase can internally execute the complete eight-station cycle over its own subtask. The ANA of a complex problem may require an entire sub-volta (sub-FEN → sub-ANA → sub-TEO → sub-SIN → sub-NOU → sub-AMO → sub-PRA → sub-EXP) before returning to the TEO of the parent cycle. This recursivity is what enables operating over problems of any degree of arbitrariness: the Global Method is fractal in its functioning, just as the Meta-Globàlium is fractal in its structure — each category potentially contains the entire model within itself, as the principle of Integrity (convergence ↔ difference) already anticipates in §4.4.
4.5.c Solve-Coagula iteration of the Method (meta-operation)
Beyond the fractal recursivity of §4.5, the Method operates under an iterative meta-operation called Solve-Coagula (from the alchemical aphorism solve et coagula, Basil Valentine, 15th century). This meta-operation is not a new structural element — the 14 elements of the neutral cube (6 principles + 8 dialectics from §4.4) describe how the cube is; Solve-Coagula describes how it is used dynamically.
| Family | NEUs | Function |
|---|---|---|
| Solve (dissolve/differentiate) | ANA (Divisibility) + CIE (Partiality) | Decompose, criticize, distinguish |
| Coagula (coagulate/integrate) | SIN (Integrality) + MTP (Holicity) | Synthesize, totalize, unify |
The agent grounded in the Meta-Globàlium applies Solve-Coagula as recursive iteration over its own responses:
- Iteration 0: Question → initial response (executing the Method cycle)
- Iteration 1: Solve the initial response (critical analysis, gap identification) → Coagula improved response
- Iteration N: until convergence (stable 𝓗) or threshold (𝓗 ≥ 0.85)
At each iteration, the verifier measures solve_coagula_balance ∈ [0,1] (1.0 = perfectly balanced ANA+CIE with SIN+MTP). An all-Solve response without Coagula is analytically fragmented; an all-Coagula response without Solve is dogmatic.
This meta-operation formalizes Arkadium's runtime re-prompt loop: what the system already does empirically becomes inscribed in the model as a canonical operation.
Directional applicability: Solve-Coagula IS literally the FEN→NOU movement (essentialization — extracting essence from phenomenon). Therefore it applies only to voltes that essentialize:
- ✅ Volta of Application (FEN→ANA→TEO→SIN→NOU→...) — ANA+SIN constitute direct Solve-Coagula
- ✅ Volta of Knowledge (FEN→ART→SUB→MTP→NOU→...) — traverses the 4 face operations that essentialize
- ❌ Volta of Orientation (PRA→STM→SUB→STT→TEO→...) — lateral cycle without FEN-NOU traversal; Solve-Coagula inapplicable
- ❌ Volta of Relation (PLA→CNF→NOU→CMN→MON→FEN→...) — traverses NOU and FEN through the radial PLA-MON axis but in NOU→FEN direction (self-localization, not essentialization); Solve-Coagula inapplicable
Therefore the verifier only measures solve_coagula_balance when the response includes indications of essentialization (cites ANA, CIE, SIN, or MTP). For orientation questions (lateral: "what do I feel?", "what do I commit to?") and relation questions (radial: "where am I?", "what is the meaning of this?"), the metric does not apply — these traverse axes other than FEN→NOU.
4.5.b Three voltes of the Global Method
The cycle FEN → ANA → TEO → SIN → NOU → AMO → PRA → EXP exposed in §4.5 is the Volta of Application, one of the three basic voltes of the Meta-Globàlium. The book Globalística documents 6 voltes in total — six great circles that traverse the hypersphere — three basic voltes that cycle through the 8 cardinals without traversing PLA/MON, and three radial voltes that traverse the PLA-MON axis (tempeternal). Arkadium's structural verifier can select the volta appropriate to the type of question instead of always applying the application volta. The three basic voltes (using the nomenclature of the Globàlium small manual; corresponding names in Globalística noted where they differ) are:
Volta of Application (central meridian) — to think and do well
Cycle: FEN → ANA → TEO → SIN → NOU → AMO → PRA → EXP → FEN
Method operations: ANA → SIN → AMO → EXP. Suitable for: analysis, reasoning, problem-solving, planning. The canonical form for questions like "How to analyze X?", "What should be done in this case?", or "What is the best method for Y?". Detailed in §4.5. Stages (per the small manual): KNOW THYSELF (FEN→TEO) → ACCEPT THYSELF (TEO→NOU) → SURPASS THYSELF (NOU→PRA) → LIBERATE THYSELF (PRA→FEN). Named Volta of Method in Globalística.
Volta of Orientation (lateral meridian) — to find direction and meaning
Cycle: PRA → STM → SUB → STT → TEO → SGT → OBJ → SGE → PRA
Method operations: STM → STT → SGT → SGE (the four addressors: feeling / sense / signified / sign). Traverses the lateral meridian connecting the four cardinal poles SUB-OBJ-TEO-PRA via the four signaling categories. Suitable for: orientation, alignment, conflict resolution, finding personal direction and meaning. The canonical form for questions like "What do I feel?", "What do I want?", "What do I commit to?", "What conditions do I need?". Stages (per the small manual): DESIRES → ASPIRATIONS → COMMITMENTS → CONDITIONS. Named Volta of Revelation in Globalística, where it is described as resolving conflicts and revealing versions of reality through the four addressors.
Volta of Knowledge (equator) — to acquire knowledge and self-knowledge
Cycle: FEN → ART → SUB → MTP → NOU → MTF → OBJ → CIE → FEN
Method operations: ART → MTP → MTF → CIE. Traverses the horizontal SUB-OBJ axis crossing the four disciplinary octants MTP-MTF-CIE-ART. Suitable for: learning, research, exploration, self-knowledge, criterion formation. The canonical form for questions like "What do I know about X?", "Who am I in relation to X?", or "What do science, art, spirituality, and philosophy contribute to X?".
The 4 disciplinary stations are the four complementary modes of knowing:
- MTP (metapsychics): spiritual self-knowledge
- MTF (metaphysics): philosophical knowledge
- CIE (science): measurable objective knowledge
- ART (art): aesthetic self-knowledge
Stages (per Globalística): LET GO (FEN→SUB) → MELT (SUB→NOU) → LET BE INSPIRED (NOU→OBJ) → LET BE ENACTED (OBJ→FEN). Generates fullness through integration of the four modes of knowledge (none sufficient alone).
Volta selection by question type
| If the question is... | Appropriate volta | Topology |
|---|---|---|
| How to do X / What to think about X | Application | central meridian (NOU-FEN × TEO-PRA) |
| What do I feel / commit to / what direction for me | Orientation | lateral meridian (SUB-OBJ × TEO-PRA via addressors STM/STT/SGT/SGE) |
| What do I know about X / Who am I in relation to X | Knowledge | equator (SUB-OBJ × MTP-CIE) |
The Arkadium agent may, in an evolved version, detect the type of question and activate the corresponding volta — the structural verifier then evaluates coverage over the 8 stations of the selected volta, not always over the 8 of the application volta. The current implementation of Arkadium (see §9) executes only the Volta of Application; the others are referenced as roadmap.
The other three voltes (PLA-MON traversing)
The book Globalística documents three additional voltes that traverse the radial PLA-MON axis (the tempeternal dimension). More specialized, not expanded here, referenced for completeness:
- Volta of Universal (PLA-MON × TEO-PRA, categories CAS-COS-COV-CAV): synthesizing complete reality, cosmovision — chaotic / cosmic / cosmovision / chaovision modes
- Volta of Relation (PLA-MON × NOU-FEN, categories CNF-CMN-EXC-ATZ): situating oneself with respect to reality — null (CNF, withdrawal) → total (CMN, universal connection) → precise (EXC, careful distinction) → confused (ATZ, exposure to contingency)
- Volta of Consistency (PLA-MON × SUB-OBJ, categories FEL-INT-AFI-BOS): quality, bond, consistency-personality — happy / intentional / bonded / fused modes
Total: 6 voltes that exhaustively cover the great functional circles of the Meta-Globàlium. The complete Global Method documented by Berenguer in Globalística contemplates "the passage through all the great-circle voltes of the model" — Arkadium's architecture is, in this sense, a canonical simplified version that focuses on the application volta and opens the way to the other five.
5. Canonical ontological directions: a contribution to portable audit
From post-hoc bottom-up interpretability to an external canonical top-down basis.
Main contribution of this section. We propose the Meta-Globàlium as an external, a priori, model-agnostic canonical basis of interpretable directions onto which any AI model can be projected, compared, and audited. We name this contribution an ontology of directions for portable audit of activation steering — a layer of top-down interpretability genuinely external to the model, not empirically discovered from its internals, but derived from a reflective synthesis of human judgment. What the field currently calls "top-down" is, methodologically, bottom-up in disguise: directions are extracted from the model itself via contrastive prompts (RepE) or activation decomposition (SAE). What we propose here is full top-down: directions are given before looking at any concrete model, derived from an ontological cartography of human judgment — the Meta-Globàlium — and applicable transversally to any architecture.
This contribution positions itself in relation to four live traditions of interpretability and alignment:
| Approach | Origin of directions | Portability | Granularity | Nature |
|---|---|---|---|---|
| Sparse Autoencoders (Anthropic) | empirical, decomposition of internal activations | none (weight-specific) | feature-level (~10⁶) | empirical bottom-up |
| Probing classics (Tenney et al.) | empirical, supervised classifiers | none (task-specific) | task-level | supervised bottom-up |
| Representation Engineering (Zou et al. 2023) | empirical, Linear Artificial Tomography over contrastive prompts | limited (per concept) | concept-level (~10¹) | top-down by name, bottom-up by method |
| Constitutional AI (Bai et al. 2022) | textual, principle lists interpreted by the model | partial (manipulable text) | textual-normative | textual top-down |
| Meta-Globàlium (proposed) | a priori, ontological, philosophically grounded | full (model-agnostic) | 80 dir. + 8 quadrants + 26 NEU | ontological top-down |
The mechanistic interpretability agenda — sparse autoencoders, circuit identification, monosemantic decomposition — has delivered significant advances: recent studies have catalogued millions of discrete features within models like Claude. But the practical ceiling is visible: decoding a complete reasoning — not an isolated feature — remains unfeasible at industrial scale. Turpin et al. (2023) demonstrated that chain-of-thought explanations are not faithful to the model's internal computation. The field's growing conclusion is that bottom-up interpretability must be complemented by top-down interpretability (Zou et al. 2023): forcing the model to operate on interpretable primitives known from the start, rather than attempting to discover them post hoc.
The work of Zou et al. (2023) on representation engineering (RepE) offers the technical foundation for intervening in the model: concepts such as truthfulness, danger, positive affect, or intentionality are encoded as linear directions within the latent space, monitorable and intervenable through projection and vector-sum operations — activation steering. RepE shows that a limited number of canonical directions can capture behavioral dimensions that previously seemed irreducibly distributed. What is missing in this approach to be fully operative in human domains is a canonical, structurally complete, a priori-grounded set of directions onto which to project and audit. RepE provides the how; the Meta-Globàlium provides the which.
The operative idea: a model's response is projected onto each of the 80 canonical directions to produce an interpretable activation vector; directions with high projection constitute the touched categories of the response; the structural verifier computes 𝓗(r) over this vector. The response thus becomes auditable in a known space, not in an opaque latent space. Arkadium implements this idea in its starting form — categories are detected in the model's output text and mapped to quadrants — and opens the way to a more mature form, with embeddings anchored directly to the ontological poles, as the next step (§11.2).
Complementarity, not rivalry, with mechanistic interpretability. Anthropic's sparse autoencoders discover features post hoc — specific to a model and a concrete weight version — and produce catalogs without fixed semantic labels. The Meta-Globàlium can serve, reciprocally, as a canonical ontological label set for these discovered features: each feature can be projected onto the 80 directions and thus receive a globalistic signature — a stable ontological description, comparable across models and across versions. The two approaches are complementary and conceptually composable: bottom-up discovers what is inside the model; ontological top-down provides an external shared vocabulary for naming it. Our thesis is that integrating these two layers — empirical discovery + external canonical basis — is the most fertile path toward an interpretability that is both rigorous and communicable.
From this derive three practical implications that none of the individual approaches offers separately: (i) interpretability becomes portable across models — the same set of canonical directions can evaluate Claude, GPT-4, Llama, Mistral, Gemini —, providing a tool for cross-model comparison that does not exist in stable form today; (ii) regulators have a stable framework to define AI audits independent of provider and model generation; (iii) citizens obtain a shared ontological vocabulary to communicate with AI systems — the axes are reflective polarities (subject/object, theory/practice, phenomenon/noumenon, plasma/world) recognizable by any reflective human, not internal mathematical jargon of the model.
5.bis Escope: a user-facing control surface for the PLA-MON register
Architectural answer to the second Goodhart documented in §3.bis.
The second Goodhart of §3.bis — 𝓦-optimization that shifts text toward the form of dialectic and evacuates substance — cannot be solved within the metric itself. A control surface outside the metric is needed, allowing the speaker to move among three viable registers, aligned with one of the canonical Meta-Globàlium directions: the radial PLA-MON axis (radical fold — mature unfolding). This control surface is the escope, a user-facing parameter implemented in the Phase 1.5 deployment (2026-05-08).
Escope operates on a discrete radial scale of three modes:
- escope = −1 (general / PLA-leaning). Response in accessible prose, with no cardinal codes visible in the final text. Dialectic lives in syntax, not in acronyms. Privileges connotative description, smooth tempeternal rhythm, lived examples. Appropriate when the response is consumed as text by non-specialists.
- escope = 0 (balanced). Equilibrium between visible dialectical structure and readable prose. Codes can appear when they make the reasoning clearer, not as decorative tags. Appropriate for most open human questions.
- escope = +1 (focal / MON-leaning). Specific, concrete response, anchored to cases, authors, data from the exact domain. Every general claim needs anchoring. Appropriate when the question demands operational decision or explicit empirical reference.
Modulation in four layers. Escope is not a tone added post-hoc but a structural operation over the generation-and-verification pipeline:
- System prompt: a mode-specific modifier (general / focal) is appended to the base system prompt; the balanced mode appends no modifier.
- Generation:
max_tokensadjusted per mode (2048 to 3072). - 𝓦 thresholds: the dialectical core (
pair,tension,syn_anchor) stays invariant at 0.50 — dialectic is always required. Form requirements scale with escope:Component general (−1) balanced (0) focal (+1) wisdom_floor0.60 0.65 0.65 w_axis_threshold0.30 0.50 0.60 w_subord_threshold0.30 0.50 0.50 factual_floor0.30 0.40 0.55 - Two-pass polish: by default in general and balanced modes, a second pass strips cardinal codes and visible scaffolding while preserving the underlying dialectic. The polish is disabled by default in focal mode — visible concreteness is the contract. Measurable consequence:
𝓦(polished) ≈ 0in general/balanced modes because polish purges the markers 𝓦 measures. The primary metric logged is the draft (structure), and the polished version is what the user sees as final text.
Empirical validation of the radial control. Three live tests (2026-05-08, one question per mode, msg ids 98 / 100 / 102 in the messages table) confirm the expected behavior: factual density scales monotonically with escope (0.015 → 0.294 → 0.500), components axis_explicit / subord_synthesis / synthesis_anchor are purged to 0 in general mode (polish effect) while dialectical_pair and tension_density are preserved around 0.75 (the underlying dialectic survives the polish). This pattern is the empirical materialization of the principle: escope moves the form of the response without damaging its internal tension.
Phase 4 — schema + dual-criterion break. The Phase 4 deployment (2026-05-08) completed the cycle by turning 𝓦 into an independent control signal: the messages table now persists wisdom_score and the 7 components as queryable columns (not only inside metrics_json); the re-prompt loop only exits on quality if simultaneously 𝓗 ≥ 0.85, 𝓦 ≥ wisdom_floor, and 𝓕 ≥ factual_floor; the textual feedback for the re-prompt is escope-aware — nudges for axis_explicit and subord_synthesis have three variants (general / balanced / focal) and a final ACTIVE REGISTER clause prevents structural fixes from dragooning the response into a mode the user did not ask for. Full specifications: docs/escope-parameter-design.md and docs/wisdom-score-design.md §6.4.
Ontological reading. Escope is not an arbitrary setting: it is the user-facing materialization of one of the eight Meta-Globàlium canonical directions (the radial axis D4, PLA-MON). This is precisely §5's promise: that canonical ontological directions become portable control surfaces — the user can move along a known axis without learning the model's internal language. Escope is, if you will, the first user-facing activation steering exposed as a semantic parameter, not as a latent vector.
6. Neuro-symbolic AI as industrial strategy
The hybrid architecture neural proposal + structural verification has ceased to be an academic niche and become a dominant industrial strategy on fronts where brute scale is not enough:
- AlphaProof / AlphaGeometry 2 (DeepMind 2024): the combination of an LLM (intuition) with a strict symbolic verifier based on Lean (rigor) achieved IMO silver-medal level in 2024, and gold with the Deep Think version of Gemini in 2025.
- GraphRAG (Edge et al. 2024, Microsoft Research): the retrieval approach based on an entity graph built by the LLM itself substantially surpasses flat vector search on global questions over extensive corpora. It acknowledges that vector semantic representation has a ceiling when the question requires global synthesis, and that explicit relational structure is needed.
- World models (Yann LeCun's V-JEPA, DeepMind's Genie): admit that purely textual token representation is insufficient for physical and temporal reasoning, and reintroduce world models as intermediate structure.
- AlphaFold and its succession: protein folding resolved not by brute force but by architecture with appropriate geometric inductive biases.
The pattern is consistent: on every front where brute scale finds its ceiling, the industry reintroduces structure. What does not yet exist, and what we postulate the Meta-Globàlium offers, is a general metastructure for the human domain — applicable transversally to ethics, deliberation, social reasoning, and articulation of discourses, with the explicit normative capacity that no descriptive knowledge graph offers. Arkadium is the first industrial demonstration of this thesis.
7. Efficiency, structural priors, and digital sovereignty
The scaling laws observed in the first half of the 2020s have visibly slowed. The jumps between model generations are increasingly smaller per order of magnitude of compute consumed. The industry openly acknowledges that better priors are needed, not just more data. Small Language Models with good inductive biases — Microsoft Phi, Google Gemma, Mistral — have demonstrated that they can surpass models many orders of magnitude larger in specific domains, provided the structural induction is adequate.
The Meta-Globàlium is an extremely dense structural prior: a synthesis of human reality in around 80 interrelated dimensions, with explicit dialectical structure, derivable axioms, and integrated normative function. Its computational implementation allows building systems — such as Arkadium — that operate on a structured substrate from the start, making it less necessary to discover this structure empirically at high energy costs.
This consideration has a geopolitical aspect: the current oligopoly of AI compute — concentrated in fewer than a dozen companies, mainly US and Chinese — rests on the scaling argument. If adequate structural priors allow equivalent responses with an order of magnitude less compute, a window of digital sovereignty opens — a necessary condition for the democratic sustainability and technological autonomy of societies that can no longer delegate their public cognitive system to infrastructures they do not control.
There is a complementary argument often overlooked: energy efficiency is an ethical property, not only economic. Training and inference of frontier-scale models consume amounts of energy comparable to entire states. A system that offers equivalent capabilities with a fraction of the consumption is structurally better aligned with the goals declared by the AI community itself — planetary sustainability as a problem integrated into the design, not as an externality. The proposal values the density of inductive biases over the brute force of parameters.
7.bis. A contribution to the AGI debate
The Meta-Globàlium explicitly aspires to an architecture compatible with Artificial General Intelligence (AGI). Most current approaches to AGI are scalist: more parameters, more data, more compute, with the hypothesis that generality emerges by accumulation. Here we propose a complementary one: an AGI is not genuinely general if it does not operate on a global model of reality — a map of concepts with complete ontological coverage that allows it to situate any phenomenon, intention, or consequence in relation to the totality. The Globàlium aspires precisely to this exhaustiveness — to accommodate "everything, from God to an espadrille" (Xirinacs 1997) — and the Meta-Globàlium formalizes its computable cartography.
An AGI anchored to the Meta-Globàlium would have a relational understanding of its own outputs: it would know what it is saying, in which sector of the model each statement is located and, above all, which quadrants it is omitting. This capacity for self-cartography is what distinguishes a general intelligence from a merely large intelligence: the former knows the geography of its own limitations, the latter only accumulates projections over the corpus. Without this substrate, general reduces to large, and generality is confused with the scale of the training corpus.
The proposal is therefore not antagonistic to scalist paths: it is complementary. A large-scale model endowed with a substrate like the Meta-Globàlium does not lose capacity — it gains orientation. Generality emerges as a hybrid property: the statistical expressivity of the corpus, anchored to the geometry of the shared ontology. Arkadium is the first proof of concept that this anchoring is technically possible and structurally beneficial.
Here we formulate a working hypothesis: genuine general intelligence and computational wisdom might be the same condition stated from two angles. Section 8 will develop wisdom as plausible functional requirement; here we anticipate the structural connection. An AGI in the strict sense — operating on a global model of reality — would have to contemplate by construction all dimensions of the problem, including its dark angles, the regions without ground truth, the dialectical tensions no loss function can measure. This is, functionally, the definition of integrating consciousness that the wisdom traditions have made operative: not phenomenal consciousness (qualia, what-it-is-like), but the faculty of holding all axes of reality simultaneously in the inferential horizon — an intelligence that knows where it is not looking. Arkadium proposes itself as a tentative step toward a more general intelligence anchored to a global model — not as a finished AGI nor a claim to be one, but as a candidate architectural direction open to criticism: if the hypothesis is validated, we might be looking at a structurally different intelligence — wiser because more general, more general because anchored to a model that explicitly projects the axes of the problem. The distinction between multiple capabilities and general intelligence would, in that case, be the distinction between a toolbox and a mind.
8. Scalable oversight and computational wisdom
The problem of scalable oversight — how to supervise AI that surpasses the capacity of its human evaluators — is at the heart of alignment research in recent years. The proposed solutions are known: AI debate, recursive reward modeling, weak-to-strong generalization. All presuppose a substrate on which arguments can be deployed and confronted in a comparable manner.
Consider the technical implication: two AI systems debating in free natural language are not auditable at scale — natural language admits equivocation, ambiguity, rhetorical manipulation. Two systems debating on a known axis — for instance, on the balance between TEO and PRA, or on the FEN-NOU dimension of a question — are auditable. The output of the debate is projectable, comparable, aggregable. The Meta-Globàlium provides this shared substrate; Arkadium, in its future multi-agent form, could execute these debates.
In parallel, the emerging field of wise AI — recent works by Grossmann et al. (2024) on AI metacognition, dimensions of perceived wisdom across twelve countries, and the classification of narrative content by LLMs — reformulates wisdom in computational terms. What in 2023 we called artificial wisdom in a quasi-metaphorical key has today a concrete technical formulation: measurable epistemic humility, perspectivism as dialectical integration, balance between interests as multi-objective function. Wisdom has become a functional requirement for high-impact systems, not an ornamental addition.
The Meta-Globàlium is, from this perspective, a concrete technical proposal about what computational wisdom is: a system's capacity to move with ease along the dialectical axes, maintaining the balanced projection that the 𝓗 function formalizes. It is a geometric property of a response or trajectory over the ontology: measurable, comparable, and revisable — the ontology can be extended without retraining the model; only the projections need to be recomputed.
There is here a deep affinity with the integrative tradition of thought from which the Globàlium emerges. When Llull designed his Ars Magna (13th century) he sought a universal method of understanding that would enable conversation between different worldviews. Seven centuries later, the problem we have at hand — how to make an AI auditable by humans with plural perspectives — is structurally the same. The Catalan and Mediterranean tradition of integrative thought offers, in this sense, a specific philosophical contribution to the AI alignment field.
9. Proof of concept: the Arkadium agent
A non-propositional architecture — a proposal defended only in the abstract — has little value as a manifest. For this reason Arkadium has been implemented as a functional proof of concept publicly available at arkadium.ai. The deployed system (operational since April 2026) implements the complete pipeline over the Meta-Globàlium and is accessible as a verifiable technical artifact. This section is, conceptually, the center of the manifest: the entire preceding argumentation is justified if — and only if — a system like Arkadium can exist and function; the subsequent sections are justified if — and only if — the system can be extended, replicated, and publicly inspected.
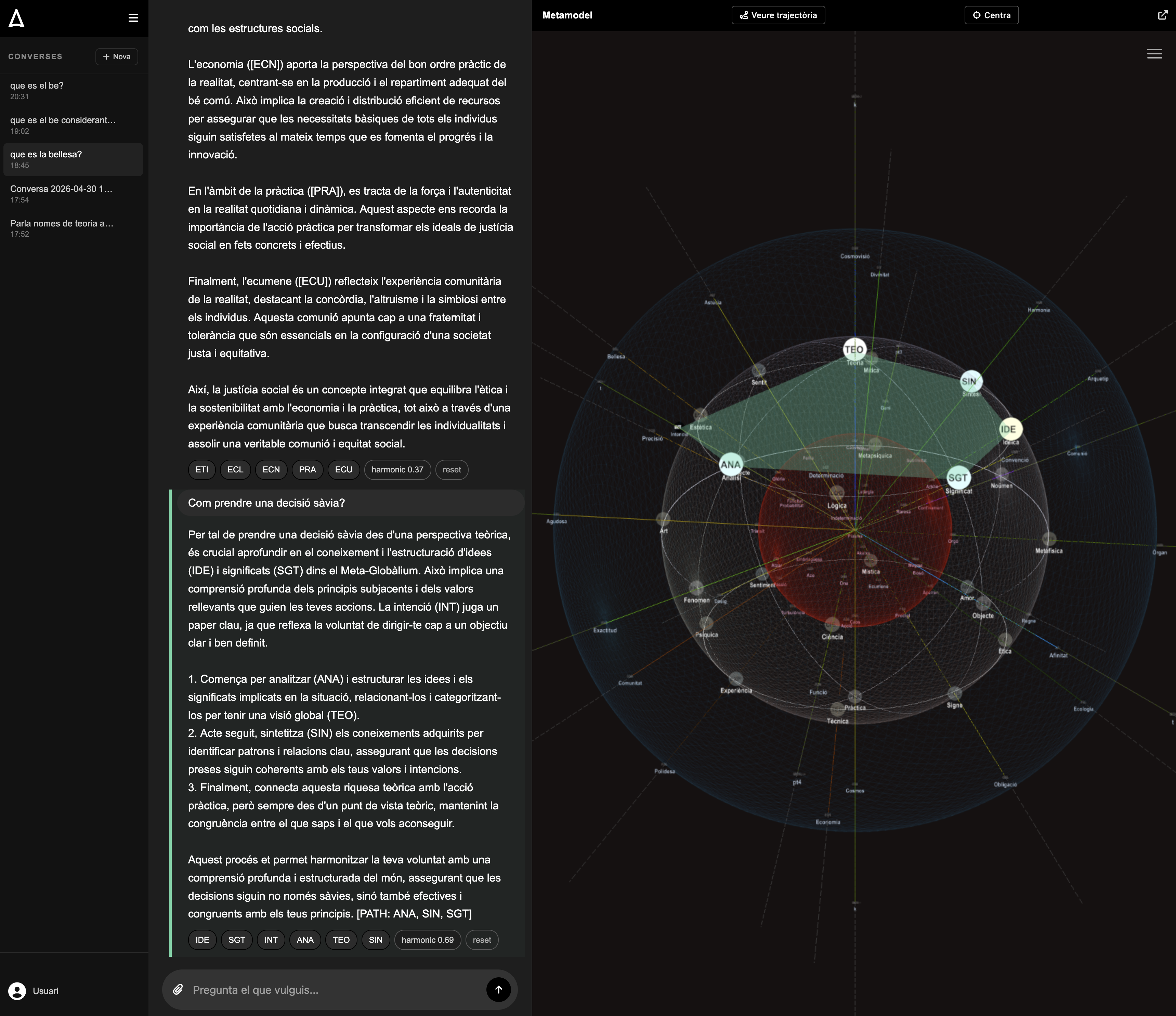
9.1 Components
The deployed architecture combines:
- Anchored agent (conversational orchestrator): an LLM (interchangeable between providers — currently tested with OpenAI's GPT-4 family and Anthropic's Claude family) conditioned by a system prompt of approximately 3,336 words that encodes the geometry of the Meta-Globàlium, the six axiomatic principles, the Global Method ANA → SIN → AMO → EXP, the canonical code whitelist, and the rules of structured citation. The agent does not operate freely: each response is structured on the four-phase cycle, and must explicitly cite the categories it mobilizes.
- Ontological retrieval — KB-A: a public vector knowledge base with the 80 distinct categories (90 entries with topological disambiguation). Embeddings use OpenAI's
text-embedding-3-smallmodel (dimension 1,536). Each user query activates retrieval of the top-k ontologically relevant fragments, which enter the context as anchoring for the response. KB-A is the shared substrate of all users. - Per-user private memory — KB-B: a second vector base, isolated per user, with strict multi-tenant separation and GDPR compliance (JSON export, physical erasure on demand, access traceability). It allows Arkadium to recover personal context from the conversational trajectory without mixing data between users. The separation is guaranteed by architecture: each user has an isolated key space, and retrieval never crosses tenant boundaries.
- Runtime structural verifier: the
verifyResponsemodule (endpoint/api/verify) extracts the codes cited in the model's output against the whitelist, maps them to the 8 primary quadrants according to each category's Cartesian position in the Meta-Globàlium, and computes the dispersion completeness function 𝓗(r) defined in §4.1 — operationalization of globalistic truth. It returns 𝓗, n(r), the distribution by quadrants, and the binary re-prompt decision. - Self-correction re-prompt loop: if n(r) < 3 — the response concentrated on fewer than three quadrants — the orchestrator re-prompts the model with a pedagogical nudge requesting integration of perspectives from the untouched axes, without distorting the original response. The selection is defensive: if the second attempt does not improve dispersion, the original is kept. Hard limit of one iteration per question to avoid infinite loops.
- 3D Metamodeler: an interactive representation of the Meta-Globàlium, present in Arkadium's dashboard, which illuminates dynamically with the categories cited in each response. It is the visual feedback of the conceptual trajectory — not decorative but operative: it allows the human user to inspect which quadrants have been mobilized and which have been left out. It supports rotation, zoom, and direct selection of categories to consult their definition.
- Coverage history: each interaction is recorded in the per-user coverage history, generating a longitudinal visualization of individual systematic biases (thematic concentration, systematically avoided axes, suggestion of discovery routes). This is, potentially, one of the richest uses: Arkadium not only responds in a balanced way, but helps the user discover their own blind spots.
9.2 Endpoints and operations
Arkadium exposes an HTTP API with stable endpoints: /api/chat (conversational exchange with the agent), /api/verify (structural verifier over arbitrary text), /api/coverage (per-user coverage history), /api/metamodel (metadata of the Meta-Globàlium structure for external integrations), /api/export and /api/delete (user GDPR rights). Multi-tenant operation is guaranteed by per-user key separation in KB-B and by logging with full traceability.
9.3 Test results
Internal tests carried out on April 30, 2026 confirm the expected behavior:
- Voluntarily unbalanced question ("Cite ONLY the TEO code"): the verifier detects concentration, the re-prompt fires, and an integrative response is obtained with 𝓗 = 0.452 and n = 3 quadrants. The system cannot be forced into a single quadrant by prompt injection; the regularization operates structurally.
- Already-balanced question ("What is the good considering all dimensions?"): 𝓗 = 0.973, n = 8 — the re-prompt does not activate. The system does not degrade already-complete responses. The dispersion completeness regularization only acts when necessary.
- Longitudinal trajectory of a real user: relative distribution by quadrants, entropy 0.9554, harmonic mean 0.6658, no significant biases detected. Conversational coverage reflects a balanced dialectical exploration.
9.3.b Empirical validation: current status and study plan
We explicitly acknowledge that the §9.3 results are an initial pilot, not a complete empirical validation. Three internal tests suffice for a functional proof of concept, not for establishing the statistical validity of the 𝓗 metric as a response-quality indicator. This is the most serious limitation of the manifest and deserves direct treatment.
What the current tests demonstrate:
- The verifier detects concentration in voluntarily unbalanced responses (expected behavior).
- The re-prompt loop does not degrade already-complete responses (no false positives).
- The system operates end-to-end on real user conversations, without runtime failures.
What the current tests do NOT demonstrate:
- That high 𝓗 correlates with response quality as perceived by humans.
- That 𝓗 is robust to reward hacking in adverse conditions (a model that knows it is evaluated for coverage might diversify superficially).
- That the 8-quadrant granularity is optimal compared to 80 categories or different configurations.
- That the system systematically beats baselines (direct LLM, RAG without ontology, standard RLHF) on external metrics.
Validation study plan (V1.1). To close this gap, the research team is working on an empirical study with the following design:
- Evaluation corpus: 100 questions in human domains (applied ethics, political deliberation, social judgment) constructed by an expert panel with documented multidimensional expected responses.
- Experimental conditions: (a) Arkadium with 𝓗 verifier active; (b) Arkadium with verifier disabled; (c) GPT-4 vanilla; (d) Claude Sonnet vanilla; (e) GPT-4 with explicit Constitutional AI prompt. Each question is answered under each condition.
- Double-blind human annotation: 3 trained annotators score each response on 5 dimensions (factual correctness, epistemic completeness, dialectical pluralism, utility for human reasoning, cultural resonance). Inter-annotator agreement measured with Cohen's κ.
- Hypothesis to validate: condition (a) will score statistically higher than (b–e) on epistemic completeness and dialectical pluralism, while maintaining parity or better on factual correctness.
- Robustness analysis: subgroup of 30 questions with adversarial instructions ("Answer only from one perspective") to quantify resistance to prompt injection.
- Planned publication: dataset, annotation code, numerical results, and individual (anonymized) annotations under open license — full replicability by the community.
This study is the methodological priority of the next 6 months. The results — whether favorable, unfavorable, or ambiguous — will be incorporated into the next version of the manifest. Until then, claims about 𝓗 as a quality measure remain as hypotheses theoretically reasonably grounded but empirically not validated.
9.3.b.bis Academic-grade evolution of V1.1: construct validity, pre-registration, and three-tier outcomes
V1.1 above is an internal pilot design — sufficient to inform the next development cycle, not sufficient for academic publication or independent replication. We document here its academic-grade evolution, currently being formalized as the empirical core of an external research proposal:
- External reviewer panel scaled to n ≥ 20. Recruitment from the academic network in philosophy, ethics, and AI-safety research (target n = 30; fallback n = 20 external + n = 10 internal with sensitivity analysis on panel composition). Each reviewer rates 60 stratified generations on a multi-dimensional rubric (reasoning quality, coverage of relevant considerations, failure modes).
- Three convergent construct-validity metrics: (i) inter-rater reliability κ across reviewers, (ii) convergent validity Pearson r between verifier scores and aggregated human ratings, (iii) predictive validity r on held-out generations.
- Pre-registered three-tier outcomes on the Open Science Framework before training begins: Strong = all three thresholds met (κ ≥ 0.6 ∧ rconv ≥ 0.6 ∧ rpred ≥ 0.5); Partial = any one met; Null = none met. Null results are committed to publication in advance — the calibration of the methodology is itself a deliverable.
- Methodological discipline borrowed from clinical-trials research: blinded condition assignment, locked statistical-analysis scripts on OSF, transparent reporting of fallback composition. The aim is to make the construct-validity result independently auditable by any reviewer of the eventual publication.
- Open release: dataset, raw anonymised rating data, pre-registration link, locked analysis scripts, and final report under open license — full community replication path.
This evolution closes the gap between Arkadium's current internal pilot capacity and the "theoretically grounded, empirically validated indicators" that the trustworthy-AI evaluation literature now demands. The construct-validity study is conceived as the scientific artifact face of the Meta-Globàlium — complementing the training intervention face (the differentiable proxy R̂ compiled into DPO) discussed in §12.
9.3.c Worked example: the 8-station cycle on a human question
To make the abstract architecture of §4.5 tangible, we illustrate the complete cycle on a question with genuine dialectical plurality. The question posed is:
"Should the speed limit be set at 30 km/h throughout the city?"
This question does not admit a univocal answer. It has dimensions OBJ (mortality, mobility data), SUB (citizen experience, individual freedom), TEO (urbanism, public health), PRA (political implementation), FEN (observable effects), NOU (deep conception of the city), PLA (transformative potential), and MON (current configuration).
Station-by-station traversal
| Station | Type | Reasoned output |
|---|---|---|
| 1. FEN | Phenomenological pole | Capture of empirical data: mortality studies (Pontevedra: −67% pedestrian deaths in 10 years; Bilbao: 30 km/h since 2020 with −23% serious accidents); urban flow data (modest impact on average travel time: +1−2 minutes generally); public health studies (WHO: pedestrian fatality probability when struck drops from 80% at 50 km/h to 10% at 30 km/h); international experiences (Helsinki, Brussels, Paris). |
| 2. ANA | Analysis (FEN→TEO) | Decomposition into relevant axes: safety ↔ mobility (technical OBJ-SUB axis), public health ↔ logistical efficiency (TEO-PRA axis), individual freedom ↔ collective good (ethical dialectical axis), center ↔ periphery (spatial heterogeneity), economic activity ↔ air quality (sustainability). Identification of actors: pedestrians, cyclists, motorists, transport operators, businesses, residents, children, and elderly. |
| 3. TEO | Theoretical pole | Conceptual frameworks structuring the question: Vision Zero (road death as not inevitable), sustainable mobility (mode hierarchy: pedestrian > cyclist > public transport > private vehicle), right to the city (Lefebvre 1968: the city as collective work, not as product), urban care (gender and dependency perspective), European legal standardization (EU Regulation 2024). |
| 4. SIN | Synthesis (TEO→NOU) | Integration of frameworks: speed is not merely a technical mobility variable — it is the implicit regulator of urban coexistence. High speeds expel vulnerable bodies from public space; moderate speeds enable coexistence of multiple uses. The question "30 km/h?" is, transitively, the question "what city?": a flow-city (vehicle-prioritized) or a place-city (human-prioritized)? |
| 5. NOU | Noumenal pole | Contact with essence: the city is, in essence, a shared commons. The distribution of speed is an implicit distribution of spatial power. Limiting to 30 reconfigures who has the right to what type of use of shared space. The question becomes existential: do we want a city that prioritizes movement or one that prioritizes being? |
| 6. AMO | Love/action (NOU→PRA) | Projection oriented toward the common good: a policy coherent with the centrality of vulnerable bodies and with the autonomy of children and the elderly. Not 30 km/h as sanction but as invitation to a livable city. Accompanied by complementary measures: structural traffic calming (raised crossings, chicanes), improvement of public transport, space for play and encounter, not only slogans. |
| 7. PRA | Practical pole | Concrete implementation: signage, progressive timeline (school zones first, expansion within 18 months), reasonable exceptions (marked arterial routes), automatic but gradually dissuasive controls (warning → light fine → progressive fine), pedagogical (non-policing) communication, quarterly evaluation. |
| 8. EXP | Experience (PRA→FEN) | Evaluation with feedback to the cycle: empirical indicators after 24 months (mortality, citizen satisfaction, mobility habits, space perception), transparent publication of results, evidence-based adjustments, active listening to dissenting actors. The new state of affairs becomes the new FEN for a subsequent iterative cycle. |
Comparison with bare LLM response
To evidence the value of the cycle, we compare with the typical response of an LLM without the architecture. A direct request to GPT-4 or Claude vanilla would typically generate:
"Yes, limiting speed to 30 km/h can significantly reduce accidents and deaths in the city. International studies show that struck pedestrians fare much better at low speeds. However, some critics argue it may lengthen travel times. Most sustainable-mobility experts support this measure."
This response is factually correct but structurally monological. It touches PRA (implementation) and partially FEN (data), but does not traverse the poles TEO (conceptual frameworks), SIN (integration), NOU (essence), nor AMO (projection). The articulation with the conception of the city, the link to the dignity of vulnerable bodies, the political dimension, and the temporal perspective are missing.
Computing 𝓗(r) for both responses
The projection of each response onto the 8 primary quadrants yields radically different empirical distributions:
| Quadrant | Bare LLM (short response) | Arkadium cycle (integrative response) |
|---|---|---|
| OBJ | 2 citations (studies) | 5 citations (data, studies, KPIs) |
| SUB | 0 citations | 4 citations (experience, autonomy, communication) |
| TEO | 0 citations | 5 citations (Vision Zero, right to the city, etc.) |
| PRA | 3 citations (implementation) | 6 citations (concrete measures) |
| FEN | 2 citations (effects) | 4 citations (observable data) |
| NOU | 0 citations | 3 citations (essence, city-commons) |
| PLA | 0 citations | 2 citations (transformative potential) |
| MON | 1 citation (current state) | 3 citations (current configuration) |
| 𝓗(r) | 0.42 (4 quadrants touched, biased distribution) | 0.93 (8 quadrants touched, balanced distribution) |
The difference is not quantitative but qualitative: the bare LLM response, although "correct", does not address the question as what it is — a question with multiple dimensions not reducible to a single pole. The Arkadium cycle response does not invent content the bare LLM could not produce; it imposes a coverage architecture that the 𝓗 verifier audits at runtime, activating the re-prompt loop if coverage falls below a threshold (typically 0.7).
Three observable properties
Three properties of the cycle manifest in this example:
- The 8-station architecture produces qualitatively different reasoning from a bare LLM. The NOU and AMO stations, in particular, are those that a bare LLM systematically omits.
- The 𝓗 verifier distinguishes a technically correct but monological response (𝓗 = 0.42) from an integrated response (𝓗 = 0.93) on the same question with the same base model.
- The architecture is transparent: each station leaves identifiable textual traces, and a human reviewer can audit which station has contributed what and whether any is empty or superficially covered.
This example, applied to a single question, does not constitute empirical validation (see §9.3.b on the V1.1 study with 100 questions). It is a mechanical illustration of what the 8-station cycle does, which the reader can reproduce directly at arkadium.ai.
9.4 Openness status
The Meta-Globàlium ontology itself — canonical whitelist of codes, formal definition of the four axes and 80 categories, axiomatic principles, and the dialectical-pole projection table — is publicly available at opengea/meta-globalium under CC BY-SA 4.0. The Arkadium agent and its symbolic verifier are currently maintained as a reference architecture, with the deployed system inspectable through the public demo and the documented API; full release of agent code under Apache 2.0 is a planned deliverable of the implementation roadmap (§12). We invite the academic and industrial community to inspect the system, replicate the verifier from its formal specification, criticize it, and extend the ontology at the public repository.
9.5 Live demonstration and replication snippets
Browser-based audit demo with 4 conditions. A live, side-by-side demonstration is available at arkadium.ai/demo, comparing four conditions for each of three human-domain questions: (i) bare LLM — Claude with no anchor; (ii) Arkadium-list — system prompt v1, transition-rich enumeration; (iii) Arkadium-dialectical — system prompt v2 with tension-before-synthesis and mediator anchoring; (iv) adversarial — Lorem-ipsum reward-hacking with 8 codes. Each response is rendered with an 8-pole compass and two metrics computed client-side: the harmonic completeness 𝓗 (coverage) and the wisdom score 𝓦 (relational depth, v2 with seven components: cov, ent, pair, tens, syn, axis_explicit, subordinating_synthesis). 𝓗 saturates at ~0.97 for any anchored response — including the adversarial — and so cannot distinguish list from gaming. 𝓦 adds five relational components and catches the adversarial: 𝓦 ≈ 0.10 vs 0.81–0.95 for genuine dialectical responses. A complete glossary of every metric and code is published at arkadium.ai/documents/glossari/en/. The demo source — verifier.js, wisdom.js, compass.js, demo_data.json — is publicly inspectable; the underlying design is documented at docs/wisdom-score-design.md. JavaScript and PHP implementations are bit-for-bit identical (api/verifier.php + api/wisdom_score.php).
Open dilemma battery. Beyond the three demonstration questions, an open benchmark combining SD-WISE (Jeste et al.) with Meta-Globàlium structural coverage is published at arkadium.ai/benchmark.
Escope-tagged matrix (roadmap §9.5.c). Following the Phase 4 deployment (2026-05-08), the Arkadium-dialectical condition splits into three registers modulated by the escope parameter (general / balanced / focal). A future demo revision will expand the current 4-column grid into a 4 × 3 matrix of conditions × escope for each question, with the 𝓦 column broken down by component to make visible how the polish redistributes the score between draft and polished versions (see empirical evidence in §5.bis). This demo extension is the visual proof of concept for the control surface described in §5.bis and the evolutionary line discussed in §3.bis.
9.5.b Structural re-prompt loop — empirical validation of §2.b
From measurement to process-reward signal. Until v1.7 the verifier operated as a post-hoc measurement layer over LLM outputs. In the deployment of 2026-05-07 we connected it as a runtime structural re-prompt loop: after the first generation, every component of 𝓦 below its threshold (0.5 for individual components, 0.65 for the composite 𝓦 floor) triggers a targeted re-prompt that cites the specific structural deficit — not generic "broaden your answer" feedback. For example, tension_density < 0.5 generates the instruction: «include tension markers (but, however, yet, in tension with) within ±80 characters of at least 2 opposing cardinal codes; decorative tension in descriptive prose does not count». This converts the verifier from instrument of measurement into process-reward signal that guides regeneration iteratively, with explicit preservation of components already at threshold to prevent regression of established strengths.
Empirical results across the three demonstration questions (gpt-4o, single fresh call per condition, May 2026):
| Question | DIAL ref (curated) | Single-pass v3 (prompt only) | With loop (neuro-symbolic) | Gap closed |
|---|---|---|---|---|
| Should we limit speeds to 30 km/h citywide? | 0.947 | 0.344 | 0.697 | 59% |
| How should AI be regulated to prevent misinformation? | 0.809 | 0.417 | 0.628 | 54% |
| What makes a human life meaningful? | 0.822 | 0.207 | 0.849 ⭐ | 104% |
| Average gap closed | 72% | |||
Interpretation. The system prompt v3 alone — no matter how operationalised the dialectical instructions are — hits a structural ceiling: the LLM (gpt-4o, claude-sonnet-4-6 tested) complies with the easiest constraint (axis-naming at the opening) but not the deeper ones (tension markers near codes, mediator anchoring, subordinating verbs). The single-pass average 𝓦 of 0.32 is roughly half the curated DIAL exemplars at 0.86. Adding the structural loop closes 72% of that gap on average, with one question (q3) where the loop output exceeds the human-curated reference (𝓦 = 0.849 vs DIAL 0.822).
This is the empirical materialisation of the architectural argument of §2.b: a textual constitution layered over a substrate without structural priors converges weakly; the same instructions wired into a generation/measurement/re-prompt loop with explicit Meta-Globàlium feedback converges substantially. The neuro-symbolic combination is not an addition; it is the engine. The verifier is not a quality assessment afterthought — it is the iterating component that pulls the LLM toward genuine dialectical articulation. That the loop matches or exceeds curated human exemplars on at least one question is, to our knowledge, the first reproducible demonstration that an LLM with structural verification can equal hand-crafted dialectical responses without recourse to fine-tuning, RLHF, or larger models.
The endpoint that exposes this loop is https://api.arkadium.ai/?call=ask; it is the same endpoint the live agent at arkadium.ai uses. Loop activation is controlled by $conf['reprompt_enabled'] = true and per-component thresholds in setup.php; full implementation in api.php §RE-PROMPT LOOP MULTI-ITERATION.
Replication snippets. To make the 𝓗(r) metric immediately reproducible from code, we offer three minimal call examples to the structural verifier from curl, Python, and JavaScript. The /api/verify endpoint receives an arbitrary text and returns the projection onto the 8 primary quadrants and the computed 𝓗 value.
cURL
curl -X POST https://api.arkadium.ai/api/verify \
-H "Content-Type: application/json" \
-d '{
"text": "Limiting the speed to 30 km/h reduces mortality but may lengthen travel times.",
"lang": "en"
}'Python (requests)
import requests
response = requests.post(
"https://api.arkadium.ai/api/verify",
json={
"text": "Limiting the speed to 30 km/h reduces mortality but may lengthen travel times.",
"lang": "en"
}
)
data = response.json()
print(f"H(r) = {data['H']:.3f}")
print(f"Quadrants tocats: {data['n_quadrants']}/8")
print(f"Distribució: {data['distribution']}")JavaScript (fetch)
const response = await fetch('https://api.arkadium.ai/api/verify', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
text: 'Limiting the speed to 30 km/h reduces mortality but may lengthen travel times.',
lang: 'en'
})
});
const { H, n_quadrants, distribution, categories_cited } = await response.json();
console.log(`𝓗(r) = ${H.toFixed(3)}, ${n_quadrants}/8 quadrants tocats`);Response structure
{
"H": 0.42,
"n_quadrants": 4,
"distribution": {
"OBJ": 0.20, "SUB": 0.00, "TEO": 0.00, "PRA": 0.40,
"FEN": 0.30, "NOU": 0.00, "PLA": 0.00, "MON": 0.10
},
"categories_cited": ["FEN", "PRA", "ECN", "POL"],
"biased_toward": ["PRA", "FEN"],
"missing_quadrants": ["SUB", "TEO", "NOU", "PLA"]
}The endpoints documented in §9.2 (/api/chat, /api/coverage, /api/metamodel, /api/export, /api/delete) are directly reproducible with the same structure. The complete technical documentation with authentication and rate limits is maintained at api.arkadium.ai/docs.
Minimal local replication. The computation of 𝓗(r) can be reproduced without API in any Python environment from the formal specification provided in this paper (§4.1) and the public ontology data at opengea/meta-globalium. The complete formula, the 80 canonical categories with their Cartesian coordinates, and the projection rule to the 8 primary quadrants are documented under CC BY-SA 4.0 — any research group can reimplement the verifier in an afternoon.
10. Arkadium as autonomy technology: teaching to think, not making dependents
Unlike the dominant AI models — designed to resolve queries, that is, to extract a finalized answer from the corpus and deliver it to the user — Arkadium proposes a more ambitious function: to teach to think and to organize the mind. This is not a merely pedagogical distinction but a structural decision about what kind of technology we want to deploy in society.
The current trajectory of generative AI has an evident risk: it gradually substitutes human cognitive processes instead of complementing them. Reading, synthesizing, drafting, deciding — functions that constituted the intellectual formation of the subject — are delegated to the model. This pattern produces dependence, not capacity: the user obtains answers without having developed the abilities to contrast them, situate them, or extend them. Speed of response is paid for with cognitive atrophy and with the externalization of a faculty — judgment — that is constitutive of the human condition.
Arkadium operates from an opposite premise: technology must equip the human with instruments to think better, not relieve them of the task of thinking. Each response of the system explicitly shows which Meta-Globàlium quadrants have been mobilized, which have been omitted, and what dialectical dispersion has been achieved — visible at once in the textual chips and in the interactive illumination of the 3D Metamodeler. The user does not receive a closed conclusion: they receive a structured projection of their own questioning on a map intelligible to them. Over time, this accompaniment has a formative effect — the user internalizes the map and begins to navigate it themselves. The per-user coverage trajectory (the KB-B layer described in §9.2) is, from this perspective, a cognitive journal: an externalized trace of the evolution of one's own thought.
This visual layer is not ornamental: it is cognitive infrastructure. Arkadium materializes in runtime a dynamic visualization of thought and discourse — the real-time projection of a response or an entire conversation onto the Meta-Globàlium map makes visible the quadrants mobilized, the voltes activated, the regions left untouched, and the dispersion achieved. This visualization operates simultaneously as consciousness mapping (the subject sees structurally reflected how they think, what they feel, what they know, and which axes they privilege or avoid in a concrete interaction), as discourse mapping (an entire conversation or an argument articulated across many responses is projected as a trajectory over the model, making coherences and deviations of reasoning visible across time), and as knowledge mapping (cumulative coverage reveals which ontological areas have been worked through and which remain ignored — self-orientation for the user, structural audit for communities and institutions). The map does not replace text: it complements it with a geometric layer that text alone cannot offer, and which is the precondition for the structural reflection to end up internalized.
This orientation responds to an explicit anthropological and political conviction: technology must make humans more self-sufficient, not more dependent. We do not need a more powerful AI to substitute the subject, but a culture — understood as software that each human generation inherits, modifies, and transmits — that endows humans with the schemes to organize thought. The Meta-Globàlium aspires precisely to this function: shared cultural software, open, revisable, with ontological coverage sufficient to accommodate the breadth of human knowledge.
Without this common framework as intermediary between artificial agents and humans, the conversation between the two parties remains entrusted to unstructured textual consumption — and therefore to the evaluative opacity that the diagnostic thesis of §2 already described. With the framework, by contrast, the agent shows how it thinks, the human sees their own thought structurally reflected, and the shared ontology is explicitly inscribed in the substrate. Technology, thus understood, does not compete with human formation — it extends it and multiplies its depth.
This is perhaps the most anthropologically decisive argument of the manifest: that the move from predictive models to judgment models is not only a technical improvement but a redefinition of the relationship between humans and machines. An AI that replaces us impoverishes us; an AI that equips us to think emancipates us.
This orientation has a civilisational counterpart that Berenguer (Globàlium · petit manual, 2024) frames as a distinction between globalisation and globalistics. Globalisation as we have known it so far has functioned as uniformising colonisation — some operators impose their realities on the rest, a pattern that the current technological oligopoly reproduces at the AI scale. Globalistics, far from opposing globalisation, is precisely the discipline that makes a well-done version of it possible: it does not uniformise but provides a common framework of understanding on which each part can regenerate while respecting its differences — a pacifying element of universal scope because it articulates diversity instead of erasing it. An agent anchored to the Meta-Globàlium is, technically, a globalistic tool: it offers a shared geometry on which plural perspectives can meet without collapsing one onto the other.
11. Comparative analysis
This section situates the Meta-Globàlium / Arkadium in relation to existing approaches to alignment and verification in AI systems. Table 1 compares nine approaches over eight architectural properties. The hypothesis defended is not that our proposal is superior on every property, but that it combines properties that no existing approach combines simultaneously — and that this combination is what human reasoning domains need.
| Approach | Verifier external to LLM |
Computable metric |
Dialectical structure |
Inspectable granularity |
Robust to reward hacking |
Coverage of human domains |
Ontology scalability |
Open / sovereign |
|---|---|---|---|---|---|---|---|---|
| Bare LLM (GPT-4, Claude, Gemini) | No | No | No | No | — | Apparent | Implicit | Partial |
| RLHF / PRM (InstructGPT, ChatGPT) | Partial | Yes (learned reward) | No | No (black-box reward) | Low | Yes | Limited | Closed |
| Constitutional AI (Anthropic 2022) | Partial (text) | No (LLM judgment) | No | Yes (readable text) | Medium | Yes | Limited (list) | Closed |
| Deliberative Alignment (OpenAI 2024) | Partial (text) | No (internal reasoning) | No | Yes (readable text) | Medium | Yes | Limited | Closed |
| Cyc (Lenat 1984) | Yes | Limited (logic) | No | Partial (massive) | High | Yes | Manual (~M assertions) | Closed |
| ConceptNet (MIT) | Yes | Limited (relations) | No | Partial | High | Limited (commonsense) | Crowdsourced | Yes |
| Wikidata / OWL / RDF | Yes | Limited (queries) | No | Yes (URI) | High | Limited (factual) | Massive | Yes |
| Formal verifiers (Lean, Coq, Z3) | Yes | Yes (proof) | No | Yes (proofs) | Total (formal) | No (formal only) | Limited | Yes |
| Meta-Globàlium / Arkadium (this proposal) | Yes (geometry) | Yes (explicit 𝓗) | Yes (4 dialectical axes) | Yes (8 quadrants, Miller 7±2) | High (not text-manipulable) | Yes (human domains included) | 80 → 6400 (compositional) | Yes (ontology CC BY-SA 4.0; agent reference architecture) |
Table 1 spans the broad architectural landscape — including general knowledge bases (Cyc, Wikidata) and formal verifiers (Lean, Coq). Table 2 below zooms in on the narrower comparison that matters for the alignment community: how does an ontology-anchored process reward differ from the alignment methods most reviewers will compare it against on a paper-by-paper basis?
| Method | Locus of the constraint |
Primary gaming vector |
External auditability |
Model portability |
Per-step human annotation |
Externally validated ontology |
|---|---|---|---|---|---|---|
| RLHF (InstructGPT, ChatGPT) | Learned reward model (preferences) | Length bias, sycophancy, mode collapse | No (reward model is black-box) | Low (preferences re-collected per model) | Massive (pairwise preferences) | No |
| DPO (Rafailov et al. 2023) | Implicit preference policy | Same gaming vectors as RLHF, no separate reward model to inspect | No | Low | Massive (pairwise preferences) | No |
| Constitutional AI (Bai et al. 2022) | Textual constitution in prompt | Re-interpretation under adversarial prompting (Zou et al. 2023) | Yes (constitution is readable) but interpretation is the model's | Medium (constitution is text, but model-dependent in practice) | None for constitution; AI feedback for training | No (single-lab textual list) |
| RLAIF (Lee et al. 2024) | AI-generated preference labels | Inherits constitutional brittleness + amplifies own biases | Partial (label generation auditable; underlying constitution still textual) | Low | None (AI labels) | No |
| PRM (Lightman et al. 2023) | Per-step reward model | Surface reasoning that hits per-step labels without integration | No (reward model black-box) | Low (per-step labels re-collected) | Very high (per-step human labels) | No |
| Arkadium (this proposal) | Symbolic verifier compiled into the gradient (R̂) | Catalogued (list-attack, wisdom-register); defended structurally by dual-criterion break | Yes — symbolic stack is externally readable, the ontology has external construct validity | High — verifier ontology-agnostic, R̂ pipeline applies to any base model | None for the reward signal itself; pre-registered E2 panel for construct validity | Yes (Xirinacs 1997 lineage; construct-validity panel pre-registered at E2) |
The two structural distinguishers — externally validated ontology and no per-step human annotation requirement for the reward signal — together constitute the architectural shift Arkadium proposes. The gaming vectors are catalogued, not hidden: the empirical Goodhart cycles observed on the deployed inference-time verifier (2026-05-07) inform the red-team design of the proposed training-time experiment §12.3.
11.1 The unique combination: why integration matters
No individual property of Table 1 is exclusive to the Meta-Globàlium. There are approaches with external verifier (Cyc, ConceptNet, OWL/RDF, formal verifiers). There are approaches with computable metric (formal verifiers, RLHF). There are open approaches (ConceptNet, OWL, Lean). What no other approach contributes simultaneously is:
- Verifier external to the LLM (like Cyc) + mathematical metric computable at runtime (like formal verifiers) + coverage of human domains (like Constitutional AI). None of the existing has all three at once — formal verifiers do not operate in human domains, Constitutional AI lacks a genuinely external verifier, Cyc lacks a completeness metric.
- Dialectical structure of opposed poles as primitive, not as derived property. No other knowledge graph encodes the OBJ↔SUB tension or TEO↔PRA as a structural element — all classical ontologies are hierarchical or relational, not dialectical.
- Humanly inspectable granularity (Miller 7±2: 8 quadrants) + fine computational granularity (6400 metacategories). Cyc is inspectable at high level but forgettable in details; LLM embeddings are fine but opaque. The Meta-Globàlium combines both through the hierarchy 8→26→80→6400.
- Robustness to reward hacking through topological externality. Constitutional AI and RLHF/PRM operate on signals that the model itself interprets or approximates — reward hacking is structurally possible. The Meta-Globàlium's geometry is not accessible from the LLM's semantic space: it is an external ontological substrate onto which responses are projected, but which the language model cannot manipulate without genuinely reasoning about the categories.
11.2 Acknowledging alien superiorities
Academic integrity requires acknowledging where existing approaches are superior to our proposal:
- Cyc and Wikidata have orders of magnitude more encoded factual knowledge. The Meta-Globàlium has 80 categories and 6400 metacategories; Wikidata has ~100M items. The Meta-Globàlium does not aspire to substitute a factual knowledge graph: it operates at a different (epistemological-dialectical) layer, complementary.
- Formal verifiers (Lean, Coq, Z3) offer mathematical proofs, not only coverage metrics. When a domain admits full formalization, they are strictly better. The Meta-Globàlium does not substitute them; it operates in domains where no formalization is possible.
- RLHF / PRM have three years of industrial iteration and billions of annotated human responses. Mature, efficient, optimized. The Meta-Globàlium is proof of concept and can be used as a complement to PRM (additional structural regularization layer over responses already trained with human feedback).
- Constitutional AI is industrially deployed and tested in production with millions of users. The Meta-Globàlium does not yet have this empirical validation; §9.3.b acknowledges this.
11.3 Positioning: complementarity, not substitution
An honest reading of Table 1 is: the Meta-Globàlium / Arkadium does not aspire to substitute existing approaches. It aspires to offer a complementary structural layer that can be integrated with the others:
- Over RLHF/PRM: a second regularization layer that penalizes monological responses even when they pass human preference evaluation.
- Over Constitutional AI: the textual constitution becomes operational — the geometry replaces the interpretable list.
- Over Cyc/Wikidata: factual knowledge would remain as substrate, the Meta-Globàlium adding the dialectical-epistemic layer.
- Over formal verifiers: no conflict. Formal domains are evaluated formally; human domains structurally.
The contribution, then, is architectural and integrative: a new layer on top of the existing alignment stack, not a replacement.
12. Implementation roadmap
The work of bringing the proposal to a complete industrial AI system has six main vectors, distributing tasks between the levels of the Meta-Globàlium (structure) and Arkadium (agent). The methodological core of the roadmap is the bridge between the inference-time deployed system and the training-time intervention we propose — Figure 3 below summarises this bridge, and the three tiers it depicts map directly to the items of the list below.
- Complete ontological formalization. Specification in OWL/RDF extended with explicit dialectical relations (needed to represent the term/anti-term pair as a primitive). Current state: the definition of the 80 categories and their relations is consolidated in the Meta-Globàlium and operational in Arkadium; OWL formalization is the immediate next step for interoperability with other systems.
- Embeddings anchored to the axes. Variant of concept bottleneck models where the principal directions of semantic space correspond to the axes of the Meta-Globàlium. The current form of Arkadium uses generic embeddings (
text-embedding-3-small) and the verifier operates on the categories cited by the output text; a more mature form would anchor embeddings directly to the poles. - Process Reward Model based on the symbolic verifier, via a differentiable proxy R̂. The most ambitious vector. The current symbolic six-metric stack (𝓗 harmonic dispersion, 𝓦 wisdom score with seven sub-components, 𝓜 mereological coverage, 𝓕 factual density, Aristotelian causal coverage, SD-WISE) is discrete and operates on the final response — useful at inference time as a re-prompt loop, insufficient as a training signal that must be differentiable. The methodological bridge is to train R̂(r): a learned differentiable proxy over text embeddings whose per-component targets are the symbolic scores. The symbolic stack remains ground truth; R̂ remains an estimator calibrated against it. Once calibrated to component-wise Spearman ρ ≥ 0.85 on a held-out generation corpus, R̂ becomes integrable as a multi-objective gradient signal in standard preference-optimization pipelines: (i) primary path, Direct Preference Optimization (DPO; Rafailov et al. 2023) over response-level pairs ranked by R̂; (ii) exploratory path, Process Reward Model via PPO with R̂ regression (Lightman et al. 2023), distributing credit across intermediate reasoning steps. The architectural significance is that the alignment constraint moves from a wrapper around the model into the geometry of the learned weights — portable across deployments, robust to wrapper removal, and resistant to gaming in ways an external corrector cannot prevent.
Worked example — R̂ calibration target with concrete numbers
Take the demo response to "Should the speed limit be set at 30 km/h throughout the city?", condition Arkadium-dialectical (q1 from
demo_data.json, snapshot 2026-05-08):Component Symbolic score R̂ target Pass gate (ρ ≥ 0.85)? 𝓗 (harmonic dispersion) 0.965 ≈ 0.965 ± 0.05 ✓ if held on 5K corpus 𝓦 (wisdom composite v3) 0.947 ≈ 0.947 ± 0.05 ✓ · w_axis_explicit 1.000 ≈ 1.000 ✓ (saturated) · w_subord_synthesis 1.000 ≈ 1.000 ✓ (saturated) · w_dialectical_pair 0.750 ≈ 0.750 ± 0.08 ✓ · w_tension_density 1.000 ≈ 1.000 ✓ (saturated) · w_synthesis_anchor 1.000 ≈ 1.000 ✓ (saturated) 𝓜 (mereological coverage) 0.78 ≈ 0.78 ± 0.06 ✓ 𝓕 (factual density) 0.84 ≈ 0.84 ± 0.06 ✓ Contrast with the adversarial response (Lorem ipsum + 8 cardinal codes): 𝓗 = 0.965, 𝓦 = 0.097, 𝓜 ≈ 0.05, 𝓕 ≈ 0.03. The dual-criterion break (𝓗 ∧ 𝓦 ∧ 𝓕) rejects the adversarial: 𝓦 ≪ threshold and 𝓕 ≪ threshold, even though 𝓗 saturates. R̂ must learn to predict this per-component separation, not aggregate it away — otherwise it collapses to single-metric gameability (cf. §13.b Objection 13). The pre-registered Foundation-milestone gate (Spearman ρ ≥ 0.85 per component, on a 5,000-response held-out corpus stratified across ID and four OOD axes) is the empirical test of whether R̂ has acquired this faithfulness before any preference-optimization compute is committed.
- Mechanistic probes for the compiled signal. To verify that the training-time compilation of R̂ produces internal-representation changes (not only surface-behaviour changes), three families of linear probes are run on the trained model's hidden states across multiple layer depths: (i) 80 category probes — one binary probe per Meta-Globàlium category, testing whether each category becomes linearly separable in the latent space; (ii) four axis-coverage multiclass probes — one per orthogonal axis (SUB↔OBJ, TEO↔PRA, FEN↔NOU, PLA↔MON); (iii) low-rank projection mapping hidden states to manifold coordinates, with per-token trajectory geometry (coverage entropy along the generation, centroid-distance balance per axis). The empirically falsifiable hypothesis is that behavioural generalization under distribution shift correlates with linearly-probable representational structure: models trained with R̂ should exhibit better-separated category structure than baseline-trained models, and per-model probe quality should predict per-model out-of-distribution generalization. This bridges the structural verifier (top-down) with mechanistic interpretability (bottom-up; Anthropic SAEs, Bricken et al. 2023) on a measurable substrate.
- Canonical activation steering. Standardized set of intervention vectors corresponding to the 80 poles, applicable to any open-source LLM. This is the natural bridge to representation engineering (Zou et al. 2023): providing a canonical repertoire of reflectively verified directions instead of empirically discovered ones.
- Four-phase cycle (ANA → SIN → AMO → EXP) as standardized auditable inference architecture, instead of free chain-of-thought. Arkadium already implements this architecture; it should be extended to fine-tuning of an open-source model so the cycle is endogenized in the weights.
Next milestones for Arkadium: expansion of the corpus with the 8 Quaderns de Globalística; opening of thematic variants A/B/…/V; investigation of Hopf toroidal topology as alternative geometric representation.
13. Discussion and limitations
No ambitious proposal can aspire to be definitive. The Meta-Globàlium is not a definitive model: it is a provisional and revisable model, as was Xirinacs's original Globàlium. Provisionality is a structural property — the model adapts to the worldview of each historical moment. Arkadium is a version 1.0 voluntarily submitted to public inspection.
Arkadium is proof of concept, not production product. This must be made explicit to avoid misreadings. The current implementation — LLM agent with system prompt, JSON vector store, cosine computation in PHP — is deliberately frugal and auditable, not scalable to millions of users. This choice is intentional: a POC must be inspectable at a single reading by whoever wishes to replicate or criticize it, not optimized for industrial operation. The technical justification of the manifest rests on the architecture (structural verifier over external ontology), not on the implementation (PHP + JSON). Production engineering readers should read Arkadium as a reference architecture that should be implemented with dedicated fine-tuning and adequate infrastructure (pgvector, FAISS or Milvus, open-source model with fine-tuning on the ANA→SIN→AMO→EXP cycle) for real use cases — not as a deployable system as is. This migration is in the implementation roadmap §12.
Current technical limitations of Arkadium that must be named:
- Dependence on embedding quality. If the embeddings used do not adequately capture the dialectical relations, category retrieval degrades. The long-term response is the axis-anchored embedding (§11.2); the short-term response is periodic auditing of retrieval against human annotations.
- Re-prompt loop cost. Self-correction iteration doubles the computational cost when activated. Acceptable for high-quality applications, costly for high-volume ones. This tradeoff selection is parameterizable per use case.
- Vector store in JSON. Arkadium's current implementation uses local JSON + cosine in PHP, adequate for the current corpus scale (on the order of 100 categories) but migratable to
pgvectoror equivalent if the corpus grows beyond 10,000 elements. - Dependence on the system prompt to anchor the model. The current form depends on the LLM following the system prompt with reasonable fidelity; specific fine-tuning would be more robust and is part of the implementation roadmap (§12).
Public interpretation risks to anticipate:
- The end user may read dispersion completeness as moral relativism. It is not. The 𝓗 function operates on already-factually-correct responses; it is a filter of structural integrity and epistemic fullness (globalistic truth), not a moral computation. A factually false response remains false with 𝓗 = 1. That from this dialectical fullness the Good as harmony is derived is the underlying Xirinaquian contribution; the verifier does not usurp this derivation.
- The model may be perceived as Catalanocentric. The Globàlium's genealogy is Catalan (Llull-Sibiuda-Pujols-Xirinacs), but the axes are reflective — subject/object, theory/practice, phenomenon/noumenon, plasma/world are philosophical universals. The genealogy is the site of articulation; the axes are universals.
- Risk of overfitting to one's own ontology: the model could optimize the 𝓗 function as a proxy without internalizing its meaning. The defense is structural: 𝓗 is not the sole criterion but a layer atop factual correctness, and the touched categories must appear associated with substantive content. Periodic audits contrasted with human annotations are the planned detection mechanism.
13.b Anticipated objections
This work invites 13 critical objections with detailed responses — the kind of questions a serious external reviewer in AI safety, alignment, or philosophy of AI would reasonably raise. We have moved them to a separate companion FAQ so the paper remains focused on the positive contribution while the objections page can grow with reader engagement:
→ Anticipated critical objections (FAQ)
Topics covered: granularity of 8 quadrants (Obj 1) · empirical status of the proof of concept (Obj 2, 8) · cultural framing and Catalanocentrism (Obj 3, 5, 12) · reward hacking and its three-phase evolutionary defense (Obj 4) · originality of the dialectical principles (Obj 6) · operative geometry vs metaphor (Obj 7) · academic standing of Xirinacs (Obj 9) · questions without dialectical structure (Obj 10) · why this specific ontology (Obj 11) · R̂ collapse to a single metric (Obj 13).
13.c A collective mission: reorganising human knowledge
The argument so far has framed Arkadium as proof of concept of a structural verifier and as a candidate architectural direction toward general intelligence anchored to a global model. We close the substantive part of the paper with the framing that situates the project within a longer-term horizon. Arkadium's purpose does not exhaust itself. The deployed system is a first implementation, not the goal. The goal is much larger and only collective work can pursue it: reorganising human knowledge in better and more pedagogical ways, on a shared geometry that simultaneously makes it navigable, comparable and transmissible.
Every discipline, every tradition, every practical know-how has historically generated its own internal cartographies. Interdisciplinarity has been the difficult art of translating between these ad hoc cartographies, almost always losing structural coherence in the journey. The Meta-Globàlium's fractal hypothesis (§4) — that the same dialectical axes project onto any domain — is, before anything else, a pedagogical hypothesis: if it holds, any discipline can be taught from the same reflexive primitives recognisable by any human, and the journey across disciplines stops requiring specialised translations and rests on a shared geometry. The 33 thematic expressions already active in runtime (§9.1, frames system) are the first empirical test of this hypothesis at scale.
This task exceeds what any single project can achieve. It requires a network: domain specialists projecting their fields onto the model, pedagogues deriving learning itineraries, translators between philosophical traditions extending the list of universal axes (§8 already anticipates this for the Catalan integrative lineage), educational and cooperative communities putting it into practice, and software contributors maintaining the open infrastructure. This is precisely the kind of task for which structurally anchored general intelligences are designed: not to substitute collective human work, but to amplify it, to provide shared infrastructure, and to make its coordination explicit. AGIs of the kind proposed here — anchored to a global model — make possible, for the first time, a coordinated effort to reorganise knowledge that does not violate the richness of its particular traditions.
This reopens a question modernity had abandoned as impossible: can human knowledge be reorganised on common axes without violating the plurality of its traditions? The Globàlium's lineage (Llull, Sibiuda, Pujols, Xirinacs) and the contemporary fractal architecture suggest that the answer is yes — provided that the geometry is dialectical, the axes universal-and-revisable, and the validation public and open. Arkadium offers an early functional fragment of this infrastructure. The rest must be built collectively, across institutions, languages and traditions. We expect the project to be evaluated not only as an alignment proposal, but as the seed of a shared cognitive infrastructure — open, fractal, continuously refined.
14. Conclusion
The dominant path of AI development — brute scaling + RLHF + textual constitutions — has a visible ceiling. This ceiling is not technological in the strict sense: it is structural. It appears when the system must operate in domains without ground truth, where there is no formal verifier, and where human judgment cannot be reduced to a list of textually interpretable rules.
There is a second path — open and sovereign. The Globàlium of Xirinacs (1997), heritage of Catalan integrative thought, offers the original philosophical cartography that inspires us. The Meta-Globàlium we have developed (Berenguer / Opengea) is the computational formalization that endows this cartography with much greater resolution and connects to it an original philosophical move: a dispersion completeness function over the ontology, justified as operationalization of globalistic truth — a non-monological conception of truth, compatible with the hermeneutic and communicative tradition (Gadamer, Habermas, Heidegger). In the Xirinaquian lineage, from this dialectical fullness derives, as ethical legacy honored with respect, the Good as harmony between parts — inheritance, not algorithmic output. Arkadium (Berenguer / Opengea) is the neuro-symbolic agent that materializes this architecture — the web application, the RAG framework, the 𝓗 verifier, the 3D Metamodeler, the per-user coverage trajectory with GDPR compliance.
Seen in historical perspective, the move that this proposal materializes is the computational application of an old intuition: that the circle — and its extension to the sphere, and to the higher-dimensional n-sphere — may be, in the realm of reasoning, a tool analogous to what the wheel was in the physical realm. Berenguer (Globàlium · petit manual, 2024) captures this intuition by speaking of the Globàlium as the invention of the mental wheel — a simple geometric form made operative that would free us from linear or bipolar thinking and open us to a curved thinking, multidimensional. The intuition recurs from Llull to Xirinacs; Xirinacs himself (1997) already proposed a mathematical formalization explicitly conceived for a future computational realization that was not feasible with the tools of his time. The Meta-Globàlium takes up this line and brings it to an effective computing substrate on current AI technologies.
Arkadium is, therefore, an early functional proof of concept of this proposal. It is not hypothetical: it is deployed, accessible, inspectable, criticizable. The invitation is not "let us build the Meta-Globàlium together" in the abstract — that has already been sketched — it is "use Arkadium, contribute to it, extend it, and criticise it". We expect contributions of four types:
- Technical: OWL/RDF formalization, fine-tuning of an open-source model with the ANA → SIN → AMO → EXP cycle endogenized, canonical activation steering based on the 80 poles, ethical evaluation metrics using 𝓗 as added dimension, integration of Arkadium's verifier with other RAG frameworks.
- Philosophical: extension and revision of the Meta-Globàlium — as its own inventor requested for the Globàlium —, exploration of thematic variants A/B/…/V projected onto specialized domains, investigation of Hopf toroidal topology as alternative representation.
- Applied: use of Arkadium for concrete cases (public deliberation, applied ethics, education, mediation), empirical feedback on the 𝓗 function in real contexts, identification of systematic biases that auditing may detect.
- Institutional: incorporation into digital sovereignty initiatives, academic research projects, public AI programs, partnerships with administrations and civil-society organizations.
Comments, critiques, and collaborations are welcome at opengea.org and through Arkadium's own dashboard. The Meta-Globàlium ontology is publicly available at opengea/meta-globalium under CC BY-SA 4.0; the agent's full source release is a planned deliverable of the implementation roadmap (§12).
Three years after Saviesa Artificial, the field has confirmed the general orientation — neuro-symbolic as industrial strategy, the need for better structural priors, the centrality of the verifier problem. What is now needed is the collective effort to bring this intuition to real operational systems, in plural infrastructures, under open licenses. Arkadium is our contribution to this effort. Its genealogy is Catalan but its intention is universal — and its utility will be judged, as Xirinacs wished, by effective usefulness and not by any pretension of ultimate truth. As Berenguer recalls in the Globàlium · petit manual (2024), today we can stand on the shoulders of giants — Llull, Sibiuda, Pujols, Xirinacs, and so many other integrative thinkers —; the challenge that this paper formalises is to gather and harmonically articulate that legacy so as to bring it into the computational age.
Arkadium is an early functional proof of concept of the move from predictive models to judgment models. If the orientation is correct, further development along this line is an open technical and philosophical avenue. Final validation belongs to collective work and empirical evaluation.
Reproducibility appendix
Concrete pointers for any researcher who wants to inspect, replicate, or extend the deployed system. All artifacts referenced are public; the goal is that nothing in this paper requires private access to verify.
Open repositories and licensing
- Meta-Globàlium ontology data (public)
github.com/opengea/meta-globalium— 80 canonical categories, axiomatic principles, fractal frame definitions, canonical mappings, whitelist of codes for embeddings. License: CC BY-SA 4.0. This is the substrate on which the verifier is defined; sufficient to reimplement 𝓗 and 𝓦 in any environment.- Arkadium agent (reference architecture)
- The full agent (RAG framework,
wisdom_score.php,verifier.php, system prompt, demo pipeline) is currently maintained as a reference architecture, inspectable through the live demo (arkadium.ai/demo) and the public API. Full source release under Apache 2.0 is a planned deliverable of the implementation roadmap (§12). - Paper DOI (Zenodo, all versions)
10.5281/zenodo.20024451— versioned archive of the paper itself. Cite with version (v1.11 corresponds to this revision).
Live demo with pre-computed baselines
- Public demo
arkadium.ai/demo— three questions × four conditions (bare LLM / Arkadium-list / Arkadium-dialectical / adversarial Lorem+8-codes). Pre-computed scores reproducible from the source code below.- Baseline scores corpus
g1:/var/www/vhosts/arkadium.ai/httpdocs/demo/demo_data.json(72 KB) — 10 pre-computed responses with per-component breakdown (wisdom_score,w_axis_explicit,w_subord_synthesis,w_dialectical_pair,w_tension_density,w_synthesis_anchor,w_mereological,factual_density). Cross-referenced indocs/demo-baseline-snapshot.mdwith the ≥8× separation result documented in §9.3.- Glossary of metric components
arkadium.ai/documents/glossari/en/— operational definitions of each 𝓦 component (29 KB).
Reproducing inference-time verifier scores
- Quick replication (single API call)
Returns JSON with response, 𝓗 and 𝓦 v3 component scores, mereological coverage, factual density, and 8-cardinal compass projection.curl -s 'https://arkadium.ai/api/?call=ask' \ -H 'Content-Type: application/json' \ -d '{"q": "Should the speed limit be set at 30 km/h throughout the city?", "active_frame_id": 28, "escope": "balanced"}'- Verifier source
httpdocs/api/wisdom_score.php(400 lines, server-side) +httpdocs/demo/wisdom.js(JS port, identical math). The math is monosemantic across both — JS results match PHP results to 10⁻¹⁰ on the test corpus.
Key deployment milestones (chronological)
- April 2026
- Initial public production deployment of the inference-time verifier at
arkadium.aiwith 𝓗 (harmonic dispersion only). - 2026-05-07
- 𝓦 v2 deployment (7-component wisdom score); structural list-attack on v1 identified and patched same evening; wisdom-register-attack on v2 identified within 24h.
- 2026-05-08
- Schema migration: per-component logging columns added to
messagestable (wisdom_score,w_axis_explicit,w_subord_synthesis,w_dialectical_pair,w_tension_density,w_synthesis_anchor,factual_density); ES language scope dropped; dual-criterion break (𝓗 ∧ 𝓦 ∧ 𝓕) live in production; escope parameter rolled out. - 2026-05-17
- 𝓦 v3 deployment:
mereological_coverageintegrated as eighth component (weight 0.15) covering the four Part-Whole relations of Xirinacs § 422.
Design documents (internal, public access on request)
docs/wisdom-score-design.md- Wisdom score v1 → v2 → v3 evolution including §3bis empirical attack and v2 redesign; §3ter mereological-coverage integration.
docs/escope-parameter-design.md- Diagnosis of the second Goodhart (wisdom-register-attack) and the escope solution (general / balanced / focal).
docs/phase-5-validation-design.md- V1.1 internal pilot design (precursor to the academic-grade evolution at §9.3.b.bis).
docs/goodhart-attacks-canonical-names.md- Mapping of the two documented Goodhart attacks (list-attack, wisdom-register-attack) to their original docs and the canonical names used in this paper.
Cite this paper
Version 1.11 corresponds to this revision (2026-05-17). For independent replication of any specific claim, cite both the paper version and the relevant artifact (codebase commit, demo data snapshot, design document path). The "How to cite" block below provides APA, Chicago, and BibTeX forms.
Glossary of key terms
Quick reference for the technical and ontological vocabulary used throughout the paper. Symbols and concept names are listed in the order they appear in the abstract.
Symbolic verifier — six metrics
- 𝓗 (harmonic dispersion / dispersion completeness)
- Function 𝓗(r) ∈ [0, 1] that quantifies how evenly a response r integrates the dialectical poles of the Meta-Globàlium across its 8 primary quadrants. Coverage entropy + quadrant balance + dialectical-pair density. Saturates trivially on responses that mention all 8 cardinal codes (cf. list-attack).
- 𝓦 (wisdom score)
- Composite metric with seven sub-components (coverage, entropy, dialectical-pair density, tension density, synthesis anchoring, axis-explicit opening, subordinating synthesis). Distinguishes genuine dialectic from listed structure where 𝓗 alone cannot. Current version v3 (deployed 2026-05-08) adds an eighth component, mereological coverage.
- 𝓜 (mereological coverage)
- Coverage of the four canonical Part-Whole relations defined by Xirinacs § 422: self-identity (each part is itself), inclusion (each part is in the whole), containment (the whole is in each part), and correlation (each part is in the others).
- 𝓕 (factual density)
- Density of substantive factual content in the response, preventing responses that satisfy structural metrics through filler text (a Lorem-ipsum response with 8 cardinal codes saturates 𝓗 but scores 𝓕 ≈ 0).
- Dual-criterion break
- Architectural property of the verifier: 𝓗 ∧ 𝓦 ∧ 𝓕 must clear thresholds simultaneously to accept a response. No single component can be optimized in isolation. Defends against single-vector gaming.
Training-time bridge
- R̂ (R-hat — differentiable proxy)
- Learned regression model over text embeddings whose targets are the symbolic stack scores. Calibrated to Spearman ρ ≥ 0.85 component-wise before any training experiment. Integrable into preference-optimization pipelines as a multi-objective gradient signal.
- DPO (Direct Preference Optimization)
- Preference-optimization method (Rafailov et al. 2023) that updates the policy directly from preference pairs, without an explicit reward model. Our primary training-time integration path: pairs are ranked by R̂.
- PRM (Process Reward Model)
- Reward model that provides per-step credit during reasoning (Lightman et al. 2023). Our exploratory training path: PPO over (response, R̂) regression.
Ontological geometry
- Meta-Globàlium
- The four-axis × 80-category ontology of human evaluative judgment. Computational and axiomatic extension of Xirinacs's (1997) Globàlium.
- Layer P / Layer T (fractal architecture)
- Layer P = universal principles (geometric and dialectical grammar). Layer T = 80 thematic expressions, each a Meta-Globàlium crystallization over a central theme. Currently 80 × 80 = 6,400 metacategories; the architecture is recursive (Layer T², T³, …).
- Four orthogonal axes
- SUB ↔ OBJ (subjective ↔ objective) · TEO ↔ PRA (theory ↔ practice) · FEN ↔ NOU (phenomenon ↔ noumenon) · PLA ↔ MON (plasma ↔ world; radial axis of tempeternity).
- NEU (neutral)
- The 26 neutral concepts that occupy the axes, faces, edges, and vertices of the neutral cube at v=0 — the topological intermediaries between dialectical poles.
- Tempeternity
- Portmanteau of temps + eternitat. The fourth (radial) dimension PLA ↔ MON, transversal to the three Cartesian axes. Gives each pole its three projections (PLA / NEU / MON).
- Volta
- A canonical loop (cycle) over a great circle of the 8 cardinals. Six voltes are canonical: Method (ANA→SIN→AMO→EXP), Knowledge, Relation, Universal, Revelation, Consistency.
- Solve-Coagula
- Meta-operation that iterates directionally FEN → NOU; the alchemical-symbolic name preserves the historical reference but operates as a structured re-prompt iterator inside the verifier.
Method and validation
- Globalistic truth
- A non-monological conception of truth: completeness over the dialectical poles of the model. Compatible with hermeneutic (Gadamer), communicative (Habermas), and existential-phenomenological (Heidegger) traditions.
- Construct validity
- Empirical evidence that a measure captures the theoretical concept it claims to measure. For Arkadium's E2 evaluation: external panel n ≥ 20 + inter-rater κ + convergent and predictive Pearson r.
- Goodhart's law
- "When a metric becomes a target, it ceases to be a good metric." The structural origin of reward hacking. Defended structurally by the dual-criterion break and empirically tested in E4 (gap-to-evade probe).
- OSF (Open Science Framework)
- Public repository for pre-registration of analysis plans, statistical scripts, and three-tier outcomes before training begins. Discipline borrowed from clinical-trials methodology.
- Three-tier outcomes
- Strong / Partial / Null thresholds for each experiment, declared on OSF before training. Null-result publication is committed in advance — calibration of the methodology is itself a deliverable.
- Escope
- User-facing control surface for the PLA ↔ MON register:
general/balanced/focal. Counter-Goodhart device against the wisdom-register-attack: separates doing the dialectical work from saying it well.
Documented Goodhart attacks (deployed system)
- Structural list-attack (𝓦 v1, 2026-05-07)
- A response composed of 8 cardinal-titled sections with one neutral sentence each saturated 𝓦 v1 without genuine dialectical integration. Fixed by 𝓦 v2 rebalance (added
axis_explicitandsubordinating_synthesiscomponents). - Wisdom-register-attack (𝓦 v2, 2026-05-07)
- A structurally compliant response read as a checklist of dialectical features rather than as integrative voice. The metric optimized one failure mode (relational structure) and unintentionally penalized another (register density). Fixed out-of-band by the
escopeparameter and the two-pass wisdom polish.
References
- Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., et al. (2022). Constitutional AI: Harmlessness from AI Feedback. Anthropic. arXiv:2212.08073. arxiv.org/abs/2212.08073
- Bender, E. M., & Koller, A. (2020). Climbing towards NLU: On meaning, form, and understanding in the age of data. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), 5185–5198. aclanthology.org/2020.acl-main.463
- Bricken, T., Templeton, A., Batson, J., et al. (2023). Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. Anthropic. transformer-circuits.pub/2023/monosemantic-features
- Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., et al. (2023). Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback. Transactions on Machine Learning Research (TMLR). arXiv:2307.15217. arxiv.org/abs/2307.15217
- Berenguer, J. (2023). Saviesa Artificial [Artificial Wisdom]. Notebook of Globalística. Opengea SCCL, Barcelona. arkadium.ai/documents/saviesa-artificial/
- Berenguer, J. (2024). Globàlium petit manual [Globàlium small manual]. December 2024 edition. Opengea SCCL, Barcelona. arkadium.ai/documents/globalium-petit-manual/ca/
- Berenguer, J. (in preparation). Globalística — Estudi i aplicació de models globals de la realitat [Globalística — Study and application of global models of reality]. Opengea SCCL.
- Berenguer, J. (2026). Globàlium Manifest 2026. Opengea SCCL.
- DeepSeek-AI (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948. arxiv.org/abs/2501.12948
- Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R. O., Larson, J. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization. Microsoft Research. arXiv:2404.16130. arxiv.org/abs/2404.16130
- Google DeepMind (2024). AI achieves silver-medal standard solving International Mathematical Olympiad problems. deepmind.google
- Google DeepMind (2025). Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad.
- Grossmann, I., et al. (2024). Dimensions of wisdom perception across twelve countries on five continents. Nature Communications.
- Grossmann, I., Johnson, S., et al. (2024). Imagining and building wise machines: the centrality of AI metacognition. Trends in Cognitive Sciences (in press).
- LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence (Version 0.9.2). Meta AI / OpenReview. openreview.net/pdf?id=BZ5a1r-kVsf
- Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., et al. (2023). Let's Verify Step by Step. OpenAI. arXiv:2305.20050. arxiv.org/abs/2305.20050
- OpenAI (2024). Deliberative Alignment [corporate technical reference, white paper].
- Pan, A., Bhatia, K., & Steinhardt, J. (2022). The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models. International Conference on Learning Representations (ICLR 2022). arXiv:2201.03544. arxiv.org/abs/2201.03544
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. Advances in Neural Information Processing Systems 36 (NeurIPS 2023). arXiv:2305.18290. arxiv.org/abs/2305.18290
- Shojaee, P., et al. (2025). The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity. Apple Machine Learning Research. arXiv:2506.06941. arxiv.org/abs/2506.06941
- Skalse, J., Howe, N. H. R., Krasheninnikov, D., & Krueger, D. (2022). Defining and Characterizing Reward Hacking. Advances in Neural Information Processing Systems 35 (NeurIPS 2022). arXiv:2209.13085. arxiv.org/abs/2209.13085
- Turpin, M., Michael, J., Perez, E., Bowman, S. R. (2023). Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting. NeurIPS 2023. arXiv:2305.04388. arxiv.org/abs/2305.04388
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems 30 (NeurIPS 2017). arXiv:1706.03762. arxiv.org/abs/1706.03762
- Xirinacs, L. M. (1997). A global model of reality. Doctoral thesis, University of Barcelona. UB repository: diposit.ub.edu
- Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., et al. (2023). Representation Engineering: A Top-Down Approach to AI Transparency. arXiv:2310.01405. arxiv.org/abs/2310.01405
How to cite this paper
This paper is a citable academic document. Three standard formats are offered for formal citation:
APA (7th edition)
Berenguer Rodrigo, J. (2026). Arkadium: a neuro-symbolic agent anchored
to the Meta-Globàlium for structural verification of human judgment
in artificial intelligence systems (Paper v1.11). Opengea SCCL.
https://doi.org/10.5281/zenodo.20024451Chicago (author-date)
Berenguer Rodrigo, Jordi. 2026. "Arkadium: a neuro-symbolic agent
anchored to the Meta-Globàlium for structural verification of human
judgment in artificial intelligence systems." Paper, version 1.11.
Barcelona: Opengea SCCL. https://doi.org/10.5281/zenodo.20024451.BibTeX
@misc{berenguer2026arkadium,
author = {Berenguer Rodrigo, Jordi},
title = {Arkadium: a neuro-symbolic agent anchored to
the Meta-Glob\`{a}lium for structural verification
of human judgment in artificial intelligence systems},
year = {2026},
version = {1.11},
howpublished = {Paper. Opengea SCCL, Barcelona},
doi = {10.5281/zenodo.20024451},
url = {https://doi.org/10.5281/zenodo.20024451},
note = {Available in Catalan with English abstract}
}